
Depuis déjà quelques mois, on entend beaucoup parler de ces nouvelles « Vector Database » qui seraient la « mémoire » des Large-Language-Models.
Pinecone (128M$), Qdrant (28M$), Croma (18M$), il y a plusieurs dizaines de startups qui lèvent des millions et se battent dans le marché hypothétique de la recherche vectorielle.
Dans cet article, nous verrons en quoi les bases de données vectorielles sont plus une fonctionnalité qu’un produit à part entière et pourquoi elles sont déjà dépassées.
C’est quoi la recherche vectorielle?
Les modèles d’IA de type Transformer utilisés par les LLMs (mais aussi pour la génération d’image, de son, etc) possèdent une représentation interne du champ sémantique d’un texte sous la forme d’un vecteur.
Ce champ sémantique représente le « sens » du texte et il est représenté sous la forme d’un vecteur à N dimensions que l’on appelle aussi Embedding.
Par exemple, pour le modèle text-embedding-3-small d’OpenAI, le vecteur possède 1536 dimensions. C’est donc un tableau de 1536 nombres entre -1 et 1.
Ce qui est pratique avec les vecteurs c’est qu’on sait très bien les manipuler. La plupart du temps, on manipule des vecteurs en 2 ou 3 dimensions mais les opérations mathématiques peuvent aussi s’appliquer à des vecteurs de 1536 dimensions.
Il existe par exemple des méthodes pour calculer la distance entre deux vecteurs. Dans le cas d’un embedding en provenance d’un LLM, cela indiquera la proximité des champs sémantiques.
Si on résume, la recherche vectorielle c’est tout simplement de la recherche sémantique.
Bon par contre il faut être honnête, c’est de très loin la meilleure technique de recherche sémantique qu’on ait eu jusqu’à maintenant mais dans le fond ça reste simplement la dernière itération de ce champ de recherche.
Recherche vectorielle et LLMs
Une des utilisations la plus courante des LLMs est le Retrieval Augmented Generation qui consiste à palier au principal défaut des LLMs, c’est à dire un coût de ré-entrainement prohibitif sur des données récentes ou privées.
Un ré-entrainement adapté permettrait au modèle d’ingurgiter de nouvelles connaissance mais le coût en temps GPU force la plupart des acteurs à utiliser un pattern RAG à la place.
La première étape du RAG consiste à récupérer les documents susceptibles de contenir la réponse à une question posée par un utilisateur.
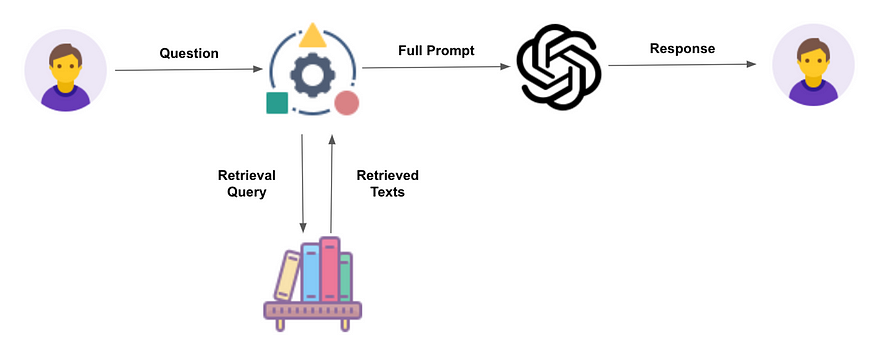
C’est à ce moment qu’intervient la recherche vectorielle, ce type de recherche sémantique va permettre de retrouver les documents pertinents dans une base de données documentaire comme la documentation interne d’une entreprise par exemple. (Voir aussi Un RAG avec la méthode HyDE : Intégration de document hypothétiques)
Une fois récupérés les documents pertinents par rapport à une question, ils seront injectés dans un prompt avec la question pour permettre au LLM de fournir une réponse spécifique en langage naturel.
Construire un véritable moteur de recherche
La recherche vectorielle offre de bons résultats pour la récupération de documents pertinents mais elle est loin d’être suffisante
Dans le monde réel, les documents ont également des métadonnées qui vont influer sur le processus de récupération.
Exemple: titre, auteur, groupe de permissions, source, type de document, etc
Permissions et filtrage
Le premier exemple concret est la gestion des permissions. Dans la plupart des entreprises, l’accès à l’information est cloisonné pour des raisons de confidentialité et de sécurité.
Il est alors impensable que le RAG puisse piocher allégrement dans des documents confidentiels réservés aux C level pour répondre à une question posée par un stagiaire.
Une étape de filtrage est alors indispensable pour écarter des résultats les documents auxquels on n’a pas accès et éviter qu’ils se retrouvent dans le prompt de génération de réponse.
Les bases de données vectorielles du marché l’ont bien compris et on voit ce genre de fonctionnalités apparaitre chez Pinecone et Qdrant par exemple.
Scoring
Ceux qui ont déjà eu à construire un moteur de recherche le savent, toutes les conditions de recherche ne se valent pas.
Dans un exemple avancé, nous pourrions décider de stocker les embedding du titre du document en plus de ceux représentant le contenu.
Exemple d’une question: Comment utiliser l’IA pédagogique de Didask?
Imaginons ensuite deux documents
- Créer des granules avec l’IA Didask: un document expliquant le fonctionnement de l’IA pédagogique
- Comparatif des IA pédagogiques: un document citant les différentes IA pédagogiques du marché ainsi que celle de Didask
Le contenu des deux documents sera sémantiquement proche de la question mais si l’on considère le contenu sémantique des titres, alors celui du document 1 est beaucoup plus proche.
Dans un véritable moteur de recherche, les documents ont chacun un score attribué en fonction de la requête et on peut naturellement configurer une importance plus grande pour le titre que pour le contenu et ajuster le score en conséquence.
Par exemple dans Elasticsearch cela se fait au moyen du mot clé boost qui permet de pondérer le score en fonction d’une sous partie de la requête comme dans notre exemple.
Langage de requête
Au delà de la recherche vectorielle, on peut vouloir appliquer des fonctions de scoring pour tout un éventail de cas d’usages.
Par exemple, il est possible d’attribuer un score plus élevé à des documents plus récents ou à des documents ayant été référencés de nombreuses fois au sein des autres documents.
En complément de la recherche vectorielle, on peut aussi utiliser des techniques plus simples comme la recherche par mot clé pour venir encore une fois donner un coup de boost supplémentaire à des documents contenant les mots clés voulus.
Finalement, la combinaisons des opérateurs avec des « AND » et des « OR » est nécessaire pour construire des requêtes complètes.
Elasticsearch: Search Engine at scale
Lorsque l’on parle de moteur de recherche, il est difficile de faire l’impasse sur le leader incontesté du domaine: Elasticsearch.
Comme toutes les bases de données vectorielles, Elasticsearch supporte les champs de type vecteur et les requêtes de proximités (knn ou plus proche voisins) permettant de faire ressortir les champs sémantiques adjacent des embedding LLM.
Elasticsearch support le scoring et aussi toute une panoplie de requêtes.
Performances
Concernant les performances, les bases de données vectorielles spécialisées ne sont même pas forcément les plus performantes.
Dans un benchmark de la fonctionnalité de recherche vectorielle de Postgres vs Pinecone, Postgres surpasse très largement Pinecone pour un coût d’infrastructure équivalent.
De son côté, Elasticsearch est un modèle de scalabilité horizontal avec des clusters atteignant jusqu’à 600 Petabytes et plusieurs millions de requêtes par jour dans certains cas.
Standard de l’industrie
Le choix d’un produit à inclure dans son infrastructure n’est pas une décision à prendre à la légère.
Plusieurs facteurs sont à prendre en compte, comme la richesse de l’écosystème en terme de SDKs, de documentation et d’hébergeur proposant le produit sur étagère ou encore la pérennité de l’entreprise développant le produit.
Aujourd’hui, les startups construisant tout leur business modèle sur une simple fonctionnalité ne sont pas certaines de toujours exister dans 5 ans alors que votre business lui existera toujours (du moins je l’espère).
Conclusion
Les bases de données vectorielles se construisent autour de la seule fonctionnalité de la recherche sémantique alors que la création d’un moteur de recherche nécessite d’aller beaucoup plus loin.
Les bases de données du marché ont déjà presque toutes leur fonctionnalité de recherche sémantique intégrée:
- Elasticsearch avec knn
- Postgres avec pg_vector
- Mongo avec Atlas Vector Search (uniquement disponible en cloud)
D’ailleurs, les véritables défis d’une base de données sont souvent ailleurs que dans une simple recherche vectorielle.
Query planner, scalabilité cluster, intégrité des données, les véritables défis sont encore à relever pour les nouvelles bases de données vectorielles alors que les bases de données existantes ont depuis longtemps fait leurs preuves.
Dans une prochaine série d’articles, j’expliquerais comment utiliser Elasticsearch et GPT4 pour créer un véritable moteur de connaissances, stay tuned 😉


