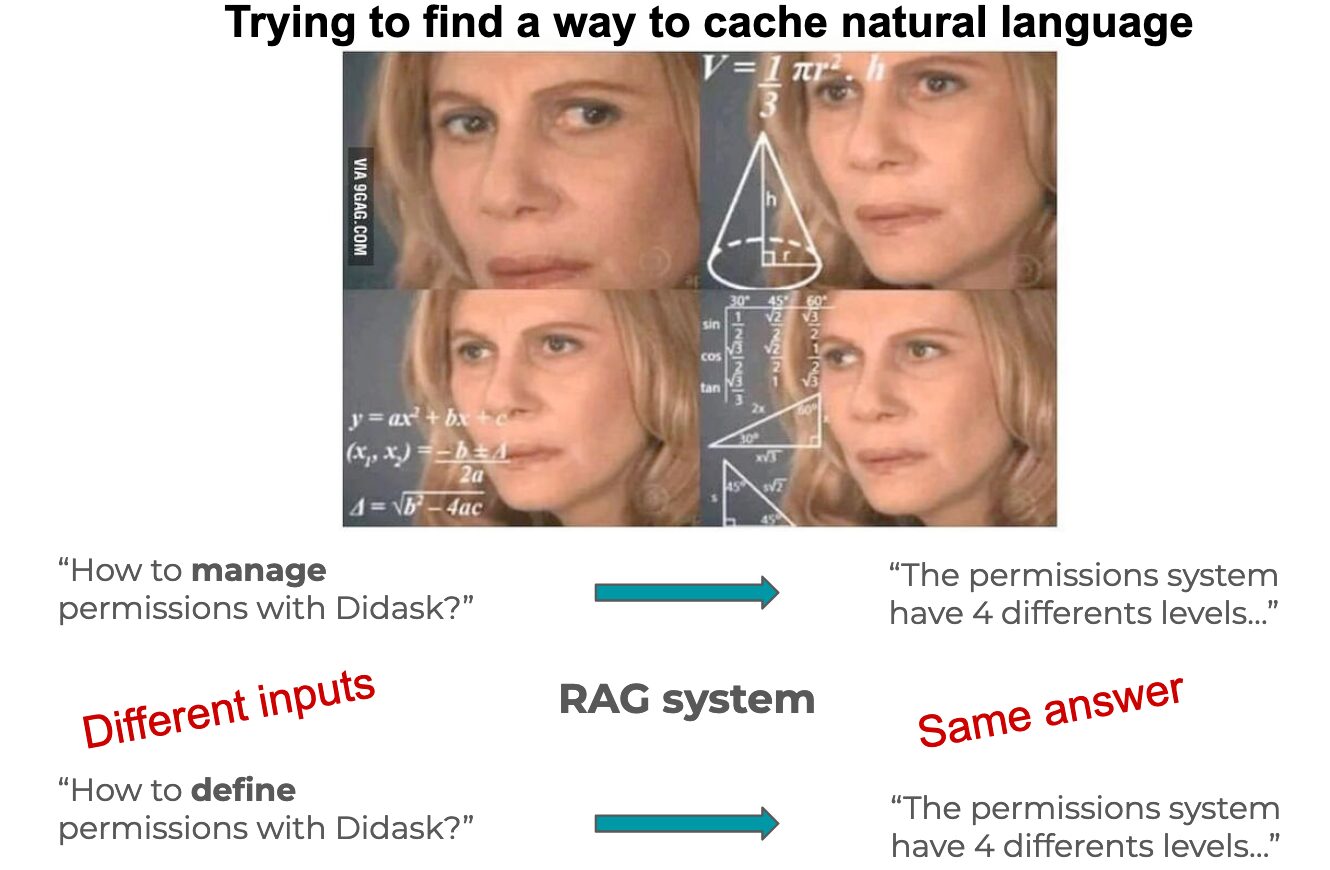
Dans le monde des Assistants IA capable de répondre aux questions, on retrouve surtout des systèmes à base de Retrieval Augmented Generation (RAG).
Les trois grands défis du RAG sont:
- retrouver les connaissances appropriées
- limiter les hallucinations
- fournir une réponse dans un temps correct
A l’instar du compromis habituel d’un projet IT entre qualité / rapidité / prix (choisissez en deux), le RAG possède donc son propre compromis entre qualité de la réponse et temps de réponse.
Après avoir beaucoup exploré la dimension qualité au détriment de la vitesse, je me suis retrouvé dans une situation la vitesse devenait réellement un problème.
Heureusement, une autre solution existe pour les bases de connaissances de taille raisonnable (< 500K tokens): le fine-tuning.
Cette technique va permettre au LLM « d’apprendre » le contenu de notre base de connaissance et nous allons voir comment procéder pour un fine-tuning de GPT-4o.
Format des données d’entrainement
La première étape est de traiter les données, la plupart des LLM attendent un format du type « message utilisateur » => « message assistant ».
Cependant, notre base de connaissance est composée de documents donc nous allons commencer créer des paires de messages.
Nous aurons deux types de paires:
- Pair de type « question/réponse »:
- U: Quelle est la date de sortie de Half-Life 2?
- A: La date de sortie de Half-Life 2 est 2004.
- Pair de type « instruction »:
- U: Liste moi les principaux protagonistes de Half-Life 2
- A: Les principaux protagonistes sont Gordon, Alyx, Eli, Isaac, Judith et Wallace
Nous utiliserons bien sur un LLM pour extraire ces paires depuis le document.
Le document contenant les données d’entrainement sera un fichier JSONL ou chaque ligne est un document avec le format suivant (mais sur une seule ligne):
{
"messages": [
{
"role": "user",
"content":
"Quel est la date de sortie de Half-Life 2?",
},
{
"role": "assistant",
"content":
"La date de sortie de Half-Life 2 est 2004.",
},
],
}Création du jeu de données d’entrainement
Plusieurs points sont à prendre en considération dans la création du jeu de données
- exhaustivité: toutes les informations contenues doivent être présente sous la forme de pairs question/réponse ou instruction
- généralisation: les formulations doivent varier afin de permettre au LLM de répondre à des situations différentes que celles des données d’entrainement
Les documents de mon jeu de données ne sont pas très gros, entre 1000 et 5000 tokens, cependant pour avoir l’ensemble des informations présentes (exhaustivité), il est préférable de découper le document pour le traiter par « chapitre ».

Découpage du document en chapitres
Pour le découpage, je vais utiliser un LLM qui devra reconnaitre des « chapitres » que je pourrais ensuite extraire du texte.
Plutôt que de lui demander de recracher le texte de chaque chapitre, je vais plutôt lui demander de me donner la ligne de début et de fin de chaque chapitre. (Je parle de cette technique pour manipuler du texte dans cet article)
Voila le workflow LLM que j’utilise:
You are an expert in extracting chapters from a document.
You will be given a document with a title and content.
You will also be given a context.
You will need to extract the chapters from the document.
You need to extract every chapter present in the document.
Those chapters are the ideas that should be memorized by learners.
A chapter can be considered as a concept, a unit of knowledge. It should not be too long.
Be explicits with list of elements.
A chapter should be self-supporting, do not create chapters that are not self-supporting.
A title should never be a chapter alone.
If the document is a table, each line is a chapter and for each value of the line, remind the name of the column.
Instead of writing the chapters, give their start div ID and end div ID.
<context>
${input.context}
</context>
<document>
${input.content}
</document>
<expected-json>
{
"chapters": [
{
"start": 1,
"end": 1
},
{
"start": 2,
"end": 4
}
]
}
</expected-json>
Start your answer with ```json and end it with ```.
DO NO WRITE ANYTHING ELSE THAN THE JSONLe contenu du document injecté a été modifié pour que chaque ligne soit contenue dans un div (e.g. <div id="1">first line</div>).
Pour les curieux, j’ai mis une partie du code que j’utilise sur Gist.
Comme pour toutes les étapes de découpage, il y a pleins de choses à faire pour l’améliorer, notamment traiter différemment les tables markdown ou s’assurer que le contexte n’est pas perdu entre chaque chapitre mais ça serait le sujet d’un article à part entière.
Génération des paires
Maintenant que l’on a découpé nos documents en chapitre, on va pouvoir générer des paires pour chacun.
La spécialisation des workflow LLM donne toujours de bons résultats alors on va en utiliser deux différents.
Pour le format question/réponse:
You are an expert in creating questions and answers from a chapter containing informations.
A business context is provided to you to understand the business.
You must transcribe all the information and concepts covered in the chapter in the form of question/answer pairs.
Alternate the way you are asking question between each question/answer pair.
<context>
${input.context}
</context>
<chapter>
${input.chapter}
</chapter>
<expected-json>
{
"pairs": [
{
"question": "What is the process for qualifying a sales lead?",
"answer": "The process involves analyzing customer data, verifying lead relevance, and assigning it to a sales representative for follow-up."
},
{
"question": "What is the role of a sales representative in qualifying a lead?",
"answer": "A sales representative is responsible for analyzing customer data, verifying lead relevance, and assigning it to a sales representative for follow-up."
}
]
}
</expected-json>
Start your answer with \`\`\`json and end it with \`\`\`.
DO NO WRITE ANYTHING ELSE THAN THE JSON
USE THE SAME LANGUAGE AS THE CHAPTERUn pour le format instruction:
You are an expert in creating instructions for a dataset.
Each instruction is composed of a question and an answer.
A business context is provided to you to understand the business.
You must transcribe all the information and concepts covered in the chapter in the form of question/answer pairs.
Alternate the way you are asking question between each question/answer pair.
<context>
${input.context}
</context>
<chapter>
${input.chapter}
</chapter>
<expected-json>
{
"pairs": [
{
"question": "Explain the steps for onboarding a new client:",
"answer": "1. Schedule a kickoff meeting. 2. Collect client data. 3. Assign account managers. 4. Set up the client in our CRM."
},
{
"question": "Provide a summary of the lead nurturing process:",
"answer": "Lead nurturing involves targeted email campaigns, regular follow-ups, and personalized content to build trust and move leads through the sales funnel."
}
]
}
</expected-json>
Start your answer with \`\`\`json and end it with \`\`\`.
DO NO WRITE ANYTHING ELSE THAN THE JSON
USE THE SAME LANGUAGE AS THE CHAPTERPour ces deux prompts, j’injecte le contenu du chapitre en cours et un texte contenant le contexte général de ma base de connaissance.
Par exemple si c’est une base de processus commerciaux d’une entreprise alors j’explique quel est le business de cette entreprise, ces clients, ces fournisseurs, bref je donne du contexte.
Je demande aussi au LLM de varier les formulations pour aider à la généralisation.
A la fin de cette étape, je me retrouve avec un fichier par document contenant les paires extraites. Je les regroupes tous dans un seul document training-dataset.jsonl dans le format attendu par OpenAI
Fine-tuning avec l’API d’OpenAI
Cette étape est la plus simple vu qu’OpenAI gère l’entrainement via son API.
Surtout que pour ce premier essai je ne me pencherais pas sur les hyperparamètres de l’entrainement et j’utiliserais les valeurs par défaut.
Le processus est le suivant:
- upload du fichier contenant les données d’entrainement
- création d’un job de fine-tuning
- récupération du status jusqu’à complétion
async function createFineTuningJob() {
try {
// Prepare the training data
const trainingFilePath = './data/training.jsonl'
// Upload the file to OpenAI
const file = await openai.files.create({
file: fs.createReadStream(trainingFilePath),
purpose: 'fine-tune',
})
// Create fine-tuning job
const fineTuningJob = await openai.fineTuning.jobs.create({
training_file: file.id,
model: 'gpt-4o-2024-08-06', // or your preferred base model
})
console.log('Fine-tuning job created:', fineTuningJob)
return fineTuningJob
} catch (error) {
console.error('Error in fine-tuning:', error)
throw error
}
}
async function getFineTuningStatus(jobId: string) {
try {
const job = await openai.fineTuning.jobs.retrieve(jobId)
console.log('Fine-tuning status:', {
status: job.status,
progress: `${job.trained_tokens ?? 0} tokens trained`,
estimatedFinish: new Date(((job.estimated_finish ?? 0) + 3600)),
finishedAt: job.finished_at,
error: job.error,
})
return job
} catch (error) {
console.error('Error retrieving job status:', error)
throw error
}
}On peut aussi tout simplement aller regarder le status des jobs depuis la console d’OpenAI.
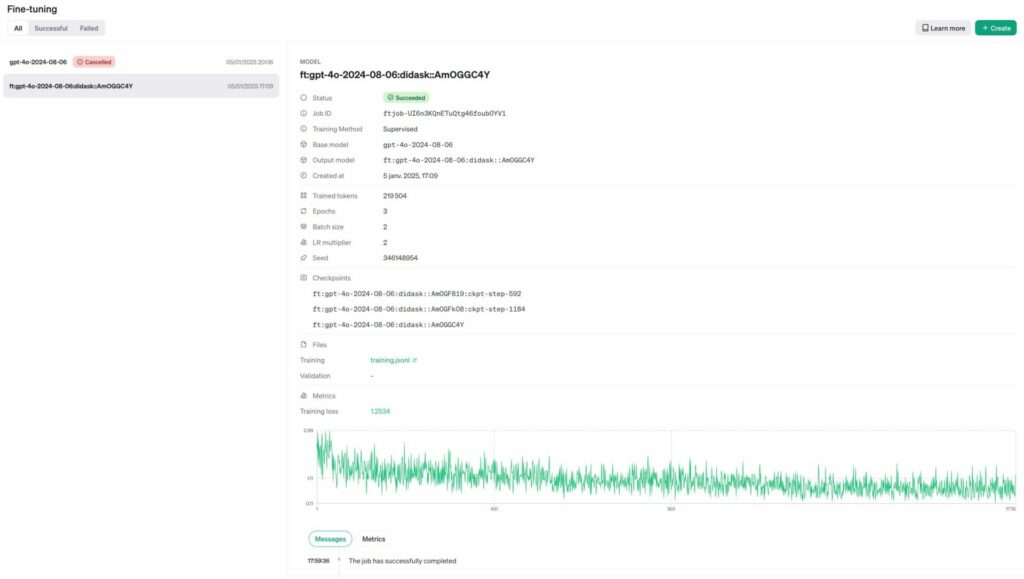
Finalement, le modèle est directement utilisable depuis le playground d’OpenAI. On peut même comparer ses réponses avec un autre modèle pour se faire une idée de la qualité du fine-tuning.
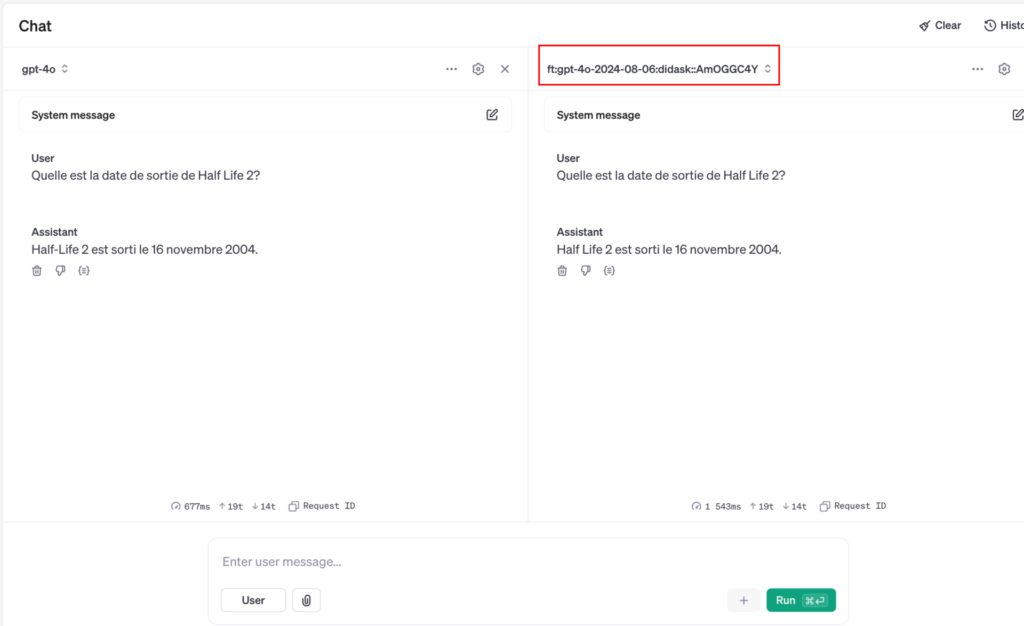
Comprendre le fine-tuning pour une base de connaissances
Le processus de fine-tuning vise à recalibrer les poids du modèles en fonction des données d’entrainement.
Le LLM utilise ces poids pour prédire un token en fonction d’une suite de tokens précedent.
On peut calculer ce qu’on appelle le « Training Loss » (la courbe verte sur le précédent screenshot) qui est un indicateur de performance sur la capacité du modèle à prédire correctement les tokens.
C’est l’indicateur utilisé par le modèle en interne pour ajuster ses poids dans le but d’améliorer le Training Loss (le faire baisser).
Plus le Training Loss est bas et plus le modèle a appris à partir des données.
Cependant un Training Loss trop bas peut aussi indiquer une situation de sur-apprentissage (« overfitting ») ou le modèle mémorise les données entrainement plutôt que de généraliser.
Dans notre situation, le sur-apprentissage est moins critique car nous avons justement besoin que le modèle mémorise les données de notre base de connaissances mais il faut quand même lui laisser de la marge pour généraliser, créer des liens entre les réponses, etc.
Limites du Fine-Tuning pour une base de connaissances
Il n’est pas possible à un LLM de désapprendre quelque chose et cela pose problème lors des mises à jour de la base de connaissance car si un fait est modifié (e.g. le prix d’un article) alors il faudra recommencer l’apprentissage de 0.
Aussi, dans le cadre d’une très grande base de connaissance, le coût de fine-tuning peut s’avérer prohibitif même pour un seul entrainement.
Finalement, il n’est pas possible de savoir quelle est la source des informations utilisées. Cela peut poser des problèmes de compréhension et de vérification des sources
Pour aller plus loin
Beaucoup de choses sont à prendre en considération pour améliorer les résultats. Machine Learning Engineer est un boulot à part entière 🙂
Fournir un jeu de données d’évaluation
Les plus attentifs auront remarqué qu’il n’y a pas la courbe de Validation Loss qui permet de vérifier que le modèle ne fait pas de sur-apprentissage.
Il serait judicieux de créer un jeu de données utiliser pour la validation et de le fournir à OpenAI pour permettre d’arrêter l’entrainement sur le modèle est trop en sur-apprentissage ou pour ajuster d’autres hyperparamètres.
Amélioration du jeu de données
En ML, la qualité des données c’est le nerfs de la guerre et dans mes tests j’ai pu constater des erreurs lors des réponses qui s’expliquent par les données fournies:
- les tables markdown sont très mal transcrites en paires, il faut un traitement spécifique pour retranscrire les informations qu’elles contiennent
- les paires sont générées uniquement sur une information particulière, il faudrait générer des paires sur des informations croisées pour aider le modèle à traiter ce genre de situations
Je pense qu’il y a pleins de pistes à explorer du côté de l’amélioration du jeu de données, c’est ici que je mettrais le plus d’efforts dans un premier temps
Évaluation
Si l’on veut être sur de la valeur ajouté du fine-tuning, il faut être en mesure d’évaluer nos résultats de manière automatique.
Cette évaluation sera similaire à celle utilisée pour un RAG, une des méthode consiste à créer des paires avec des questions et ensuite une liste de faits qui doivent être mentionnés par le LLM dans la réponse.
On demande ensuite à un « LLM as a Judge » de vérifier que chacun des faits est présent. Si certains faits ont été rajouté ou sont faux, c’est que l’on a une hallucination.
Système hybride RAG/Fine-tuning
Un compromis entre les deux modèles serait de fine-tuner un modèle sur certaines connaissances qui n’ont pas vocation à changer ou du moins pas souvent.
Cela peut être le contexte de l’entreprise et sa manière de travailler ou un lexique des termes métiers utilisés.