La recherche vectorielle d’un RAG consiste en une recherche sémantique dans nos documents.
La demande d’origine (la requête) est particulièrement importante car elle va nous donner notre vecteur utilisé dans la recherche des plus proches voisins du plan vectoriel.
Les documents qui composent notre base de données vectorielle sont très souvent issus de sources différentes et ont donc des champs sémantiques qui peuvent être assez éloignés même si ils concernent la même chose.
C’est dans ce contexte qu’intervient la méthode HyDE pour maximiser les chances de récupérer les documents en rapport avec la demande d’origine.
Génération de documents hypothétiques
Chaque source de données contient des documents ayant été écrits par des personnes aux compétences différentes et le vocabulaire utilisé est donc lui aussi différent.
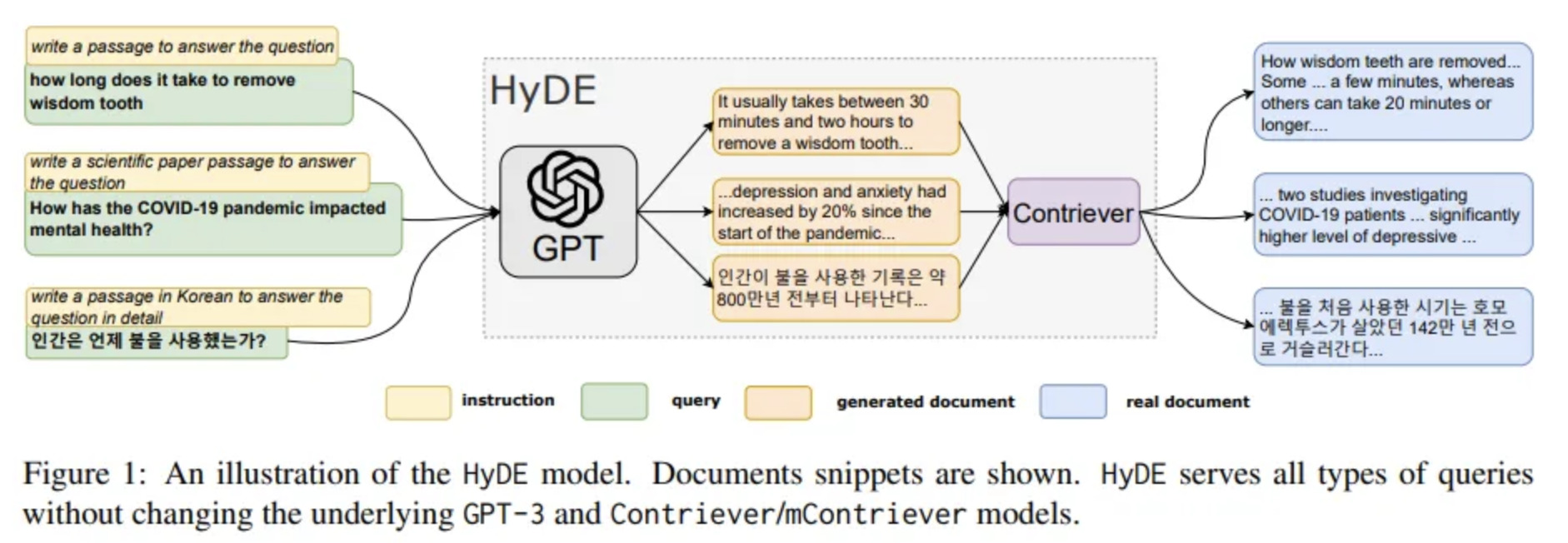
Pour tenter de se rapproche des champs sémantiques de chaque source de données, une réponse hypothétique à la demande sera générée pour chacune d’entre elle.
Bien sur cette réponse sera fausse mais le champ sémantique utilisé permettra de trouver des documents se rapprochant du sens de la demande originelle.
Prenons un exemple pour y voir plus clair, imaginons la demande suivante faite par un utilisateur de notre RAG:
Est-ce qu'il est possible de forcer un utilisateur à s'inscrire à un parcours de formation lors de la première connexion?Dans notre base de documents, 2 sources de données sont ingérées: Notion (product owners) et Github (développeurs).
Pour chaque source de données, nous allons générer des réponses hypothétiques à notre demande en utilisant le champ sémantique approprié. Bien sur on utilise GPT-4 pour cela.
Voila à quoi pourrait ressembler le prompt:
Voila une question d'un utilisateur: "Est-ce qu'il est possible de forcer un utilisateur à s'inscrire à un parcours de formation lors de la première connexion?"
Génère deux réponses hypothétiques à cette question:
- en te mettant dans la peau d'un développeur
- en te mettant dans la peau d'un product ownerPour de meilleures performances, on doit concaténer la demande à chacune des réponses hypothétiques générées.
La suite de la recherche vectorielle se fait comme dans un RAG classique.
Limites
Étant donné que l’on fait générer des réponses hypothétiques, la quantité de « bruit » va augmenter et risque de réduire la qualité des documents retournés.
La fonction de filtrage du RAG devra prendre celui en compte pour ne pas polluer le prompt final avec des documents inutiles.
Pour finir, la latence se trouvera elle aussi accrue compte tenu du fait qu’un appel de plus à un LLM doit se faire en amont du RAG.


