Malgré leurs capacités multi-modales, les LLMs fonctionnent mieux lorsqu’ils sont alimentés avec du texte.
Pour les humains, le document numérique standard c’est du PDF avec du texte, des tables et des images. Il est donc nécessaire d’extraire le contenu d’un PDF pour le fournir ensuite à un LLM.
Le format PDF étant ce qu’il est (horriblement compliqué), la plupart des techniques modernes utilisent un mélange d’extraction de texte, d’images et de reconnaissance de caractères (OCR).
Dans cet article, nous allons étudier deux solutions d’extraction de texte et d’images depuis un document PDF:
Extraction et découpage de PDF avec Reducto
Reducto propose une API en SaaS pour ingérer des documents PDF et extraire le texte et les images.
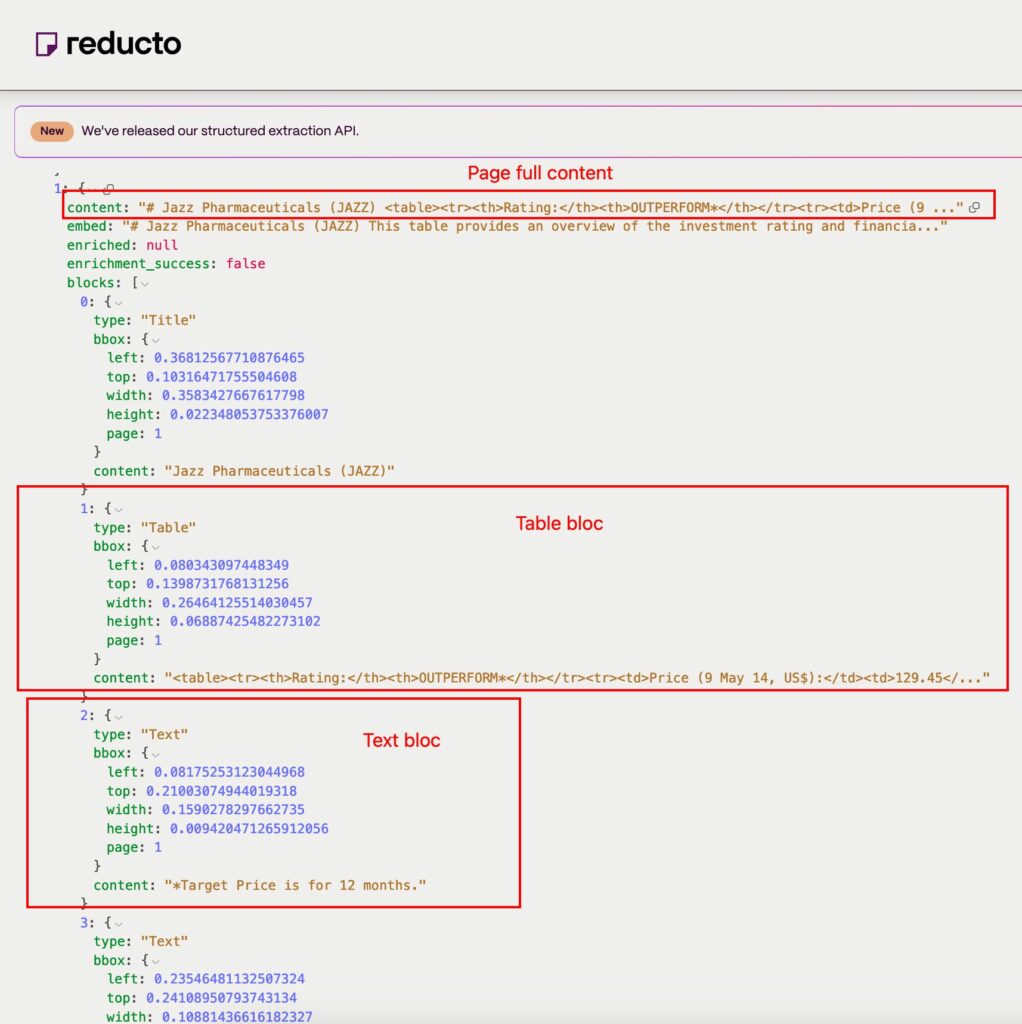
Pour chaque page, on va pouvoir récupérer le contenu texte brut avec en bonus une description des images et des tables.
On peut aussi récupérer la liste des éléments de chaque page (texte, image, table, etc) avec leur contenu et leur position sur la page.
Voir un exemple de document analysé
Reducto propose aussi de s’occuper du découpage (chunking) pour faciliter ensuite l’utilisation des données dans un système de type RAG.
Avantages:
- API en SaaS simple d’utilisation
- Extraction, description et positionnement des éléments du PDF
- Découpage pour RAG
Inconvénients:
- Pas de pay-as-you-go (300$/mois minimum, 0.02 $ la page)
- API en SaaS (question de souveraineté des données)
- Image extraites hébergées chez eux
- Auto-hébergement sur le plan enterprise seulement (>2000$/mois)
Extraction du texte et des images d’un PDF avec Marker
Marker est un outil de reconnaissance et d’extraction d’informations depuis un document PDF.
Ils utilisent leurs propres modèles de reconnaissance de PDF pour reconnaitre les différents éléments d’un PDF (table, images, texte, etc) ainsi qu’un modèle d’OCR (Surya).
Licence
Marker est en licence GPL mais les poids du modèle sont en licence cc-by-nc-sa-4.0 qui exclut les utilisations commerciales. Il faut acheter une licence On Premise à Datalab, la société qui édite Marker, pour l’utiliser sur ses propres serveurs.
Cependant, pour un usage personnel, pour la recherche ou si votre société fait moins de 5 millions de chiffre d’affaire ou si elle a levé moins de 5 millions de dollars, alors l’utilisation de Marker est gratuite.
Utilisation
Pour utiliser Marker, vous devez commencer par installer Python3 et Torch (framework de machine learning).
Pour un Mac (M3):
# Create working dir
mkdir marker-pdf && cd marker-pdf
# Install virtual env
python3 -m venv venv
# Initialize virtual env
source venv/bin/activate
# Install pytorch
pip3 install --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/cpu
# Install marker pdf
pip3 install marker-pdfVoici ensuite un exemple de script pour convertir le PDF au format markdown et sauvegarder les images.
Nous utiliserons ce PDF d’exemple issu d’un manuel scolaire.
La première fois que le code se lancera, il téléchargera les poids de tous les modèles utilisés (~2 Go en tout).
from marker.convert import convert_single_pdf
from marker.models import load_all_models
import os
fpath = "./somatosensory.pdf"
model_lst = load_all_models()
full_text, images, metadata = convert_single_pdf(fpath, model_lst)
# Create images directory if it doesn't exist
os.makedirs("images", exist_ok=True)
# Save images and create markdown content
md_content = []
# Add extracted text
md_content.append(full_text + "\n\n")
# Create doc directory if it doesn't exist
os.makedirs("doc", exist_ok=True)
# Save and link images
for image_name, image_obj in images.items():
# Save image to the images directory
image_path = os.path.join("doc", image_name)
image_obj.save(image_path)
# Write markdown file
with open("doc/result.md", "w", encoding="utf-8") as f:
f.writelines(md_content)
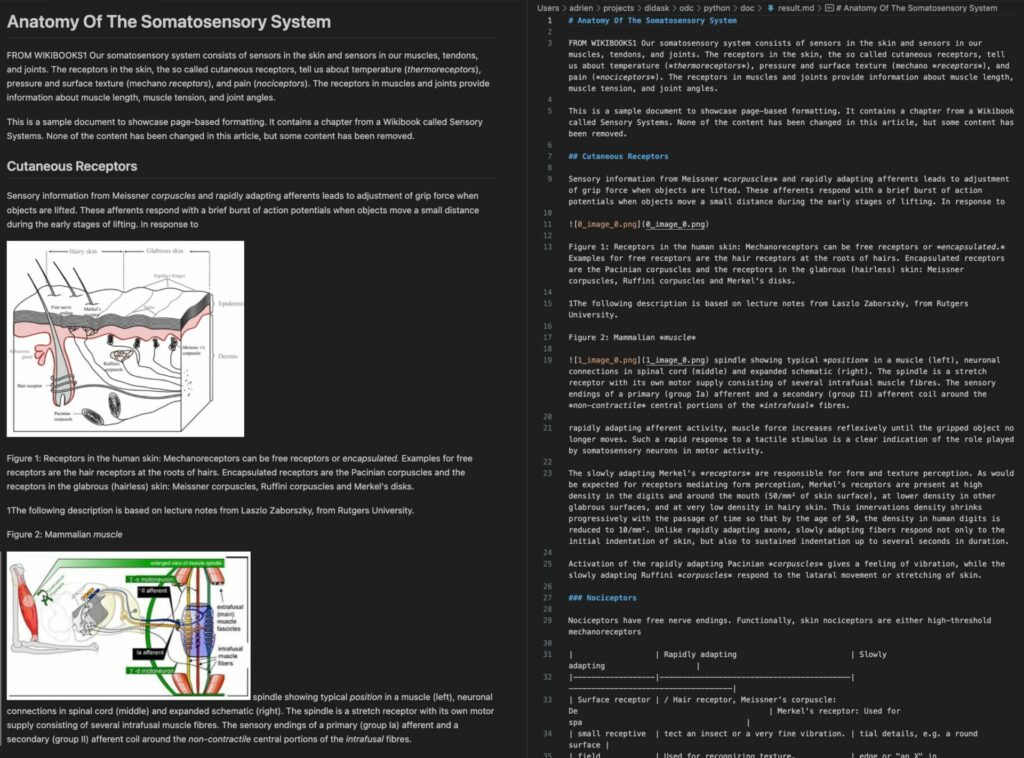
Voila le résultat du markdown généré et des images extraites:
Il est ensuite possible d’appliquer des traitements supplémentaire sur le markdown:
- description des images en utilisant un modèle de Vision
- découpage du texte en chapitre en utilisant les titres
Ces données sont ensuite prêtes à être utilisées par le pipeline d’ingestion d’un RAG.
Avantages:
- Extraction avancée des éléments avec des modèles spécialisés
- Existe en version cloud ou auto-hébergée
- Souveraineté des données dans la version auto-hébergée
Inconvénients:
- Pas de découpage intégré
- Seulement un plan payant à 5000$ (0.0025 $ la page)
- Licence auto-hébergement potentiellement cher (>5000$)
Autres solutions
- Cloud ou self-hosted
- Pay-as-you-go (0.05 ou 0.01 $ la page)
- self-hosted
- extraction séparée du texte et des images
Conversion du PDF en image et extraction des informations en utilisant un modèle de Vision comme GPT-4o.
Conclusion
Quelque soit la solution retenue, les résultats ne seront pas parfait et certaines informations peuvent être extraites de manière incorrecte.
L’extraction et le découpage de PDF est un domaine qui bouge rapidement et il vaut mieux se permettre d’expérimenter plusieurs outils avant de faire un investissement conséquent comme payer et déployer un version auto-hébergée d’un outil.