Dans un système algorithmique traditionnel, la mise en cache permet de conserver le résultat d’un calcul afin de le restituer plus tard.
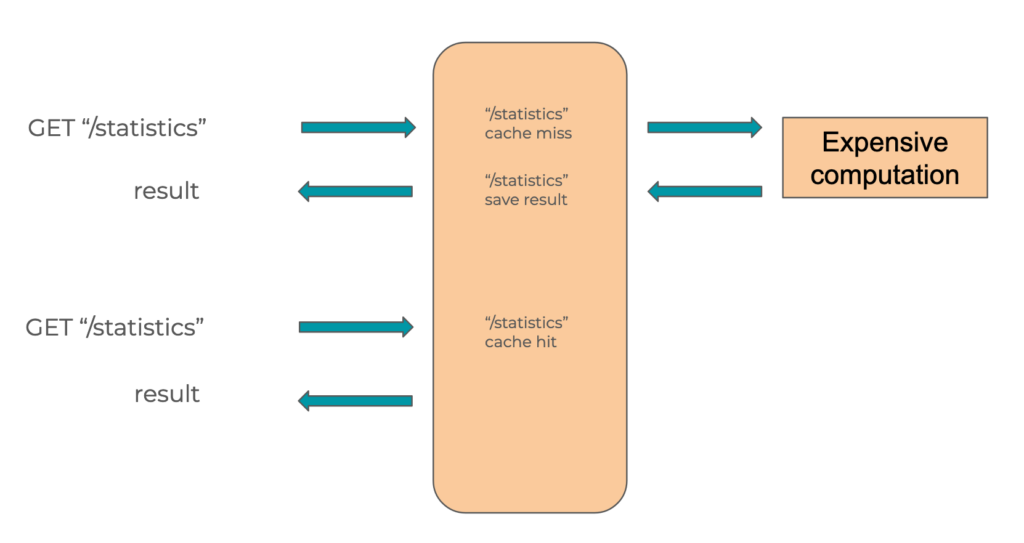
En général, on va sauvegarder le résultat d’une opération coûteuse pour le resservir directement plus tard.
On appelle généralement « clé » la valeur utilisée pour retrouver le résultat d’une opération.
Si l’on veut reproduire ce système avec un RAG, on doit prendre en compte la flexibilité sémantique du langage naturel.
Une question peut être formulée de plusieurs manières différentes et avoir la même signification, et donc la même réponse.
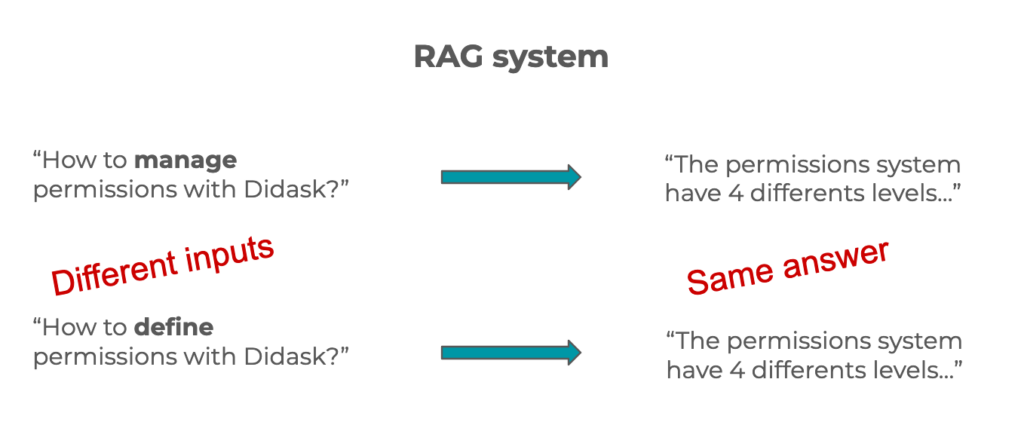
Il nous faut donc un système capable de comprendre les subtilités du langage naturel !
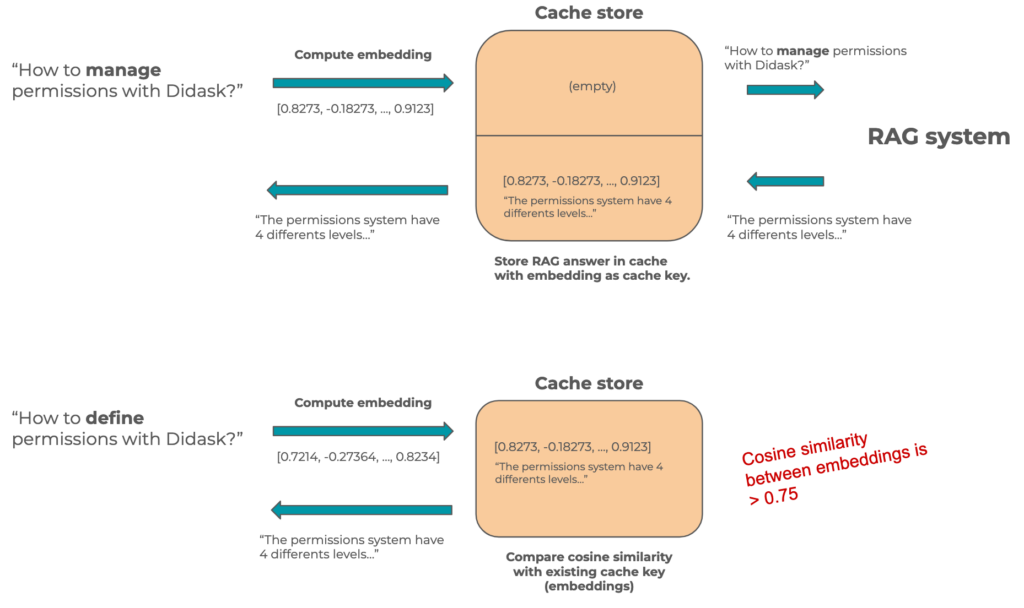
Vecteur de champ sémantique comme clé de cache
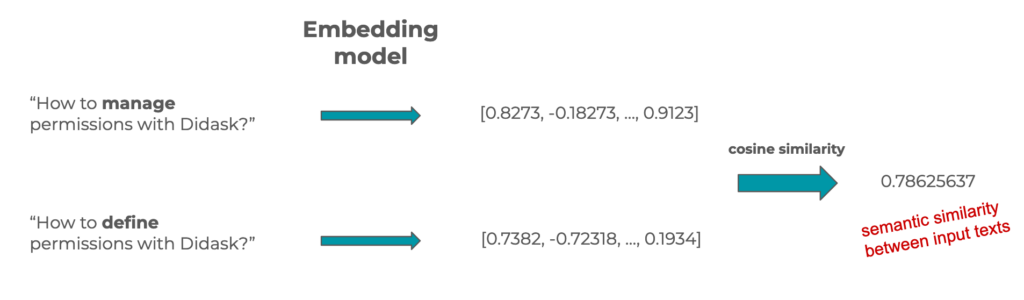
Les vecteurs de champ sémantique, ou embeddings, sont des tableaux de nombres représentant justement le sens d’un texte.
Comme ce sont des vecteurs, il est possible de les comparer et d’obtenir un nombre représentant la distance entre deux vecteurs en utilisant la similarité cosinus.
Ce nombre représente donc aussi la similarité sémantique (ou de sens) entre deux textes. C’est ce genre de technique qui est utilisée à grande échelle dans les bases de données vectorielles.
Dans un cache sémantique pour un RAG, on va donc utiliser le vecteur de champ sémantique de la question comme clé de cache et la réponse du RAG sera la valeur attachée.
Lorsque l’on reçoit une nouvelle demande en langage naturel, on cherchera si un vecteur de champ sémantique de notre cache est suffisamment similaire à celui de la demande.
Si c’est le cas, alors on peut retourner directement la réponse présente dans le cache.
« Talk is cheap, show me the code »
Pour implémenter un cache sémantique simple en Node.js, je vais avoir besoin de 3 choses:
- un modèle d’embedding (on utilisera text-embedding-3-small de OpenAI)
- un fonction de calcul de la similarité cosine
- un cache store en RAM (LRUCache)
Je vais commencer par initialiser une classe avec une méthode createEmbeddings pour demander les embedding d’un texte à OpenAI.
Je prépare aussi mon instance de LRUCache avec les embedding en clé et la réponse en valeur.
import { LRUCache } from 'lru-cache'
import OpenAI from 'openai'
const similarity: (
x: number[],
y: number[]
) => number = require('compute-cosine-similarity')
class AnswerSemanticCache {
/**
* LRUCache<questionEmbeddings, answer>
*/
private cache = new LRUCache<number[], string>({ max: 100 })
private similarityThreshold: number
private openAI: OpenAI
constructor({
similarityThreshold,
openAI,
}: {
similarityThreshold: number
openAI: OpenAI
}) {
this.similarityThreshold = similarityThreshold
this.openAI = openAI
}
private async createEmbeddings({ text }: { text: string }) {
const response = await this.openAI.embeddings.create({
input: text,
model: 'text-embedding-3-small',
})
return response.data[0].embedding
}
}Il me faut ensuite une méthode setAnswer pour sauvegarder un couple <embedding, réponse> dans mon cache:
class AnswerSemanticCache {
/**
* LRUCache<questionEmbeddings, answer>
*/
private cache = new LRUCache<number[], string>({ max: 100 })
// [...]
async setAnswer({ question, answer }: { question: string; answer: string }) {
const questionEmbeddings = await this.createEmbeddings({ text: question })
console.info(`Save answer for "${question}"`)
this.cache.set(questionEmbeddings, answer)
}
// [...]
}Finalement, la méthode getAnswer va itérer sur chaque élément du cache, calculer la similarité cosine et la comparer avec le seuil de similarité.
class AnswerSemanticCache {
/**
* LRUCache<questionEmbeddings, answer>
*/
private cache = new LRUCache<number[], string>({ max: 100 })
// [...]
async getAnswer({ question }: { question: string }) {
const embeddings = await this.createEmbeddings({ text: question })
for (const [questionEmbeddings, answer] of this.cache.entries()) {
const sim = similarity(embeddings, questionEmbeddings)
if (sim > this.similarityThreshold) {
console.info(`Cache hit for "${question}"`)
return answer
}
}
return null
}
// [...]
}On wrap ensuite le tout pour exécuter correctement notre cache (executeRAG représente la fonction qui demande une réponse à votre RAG):
const openAI = new OpenAI({ apiKey: process.env.OPENAI_API_KEY })
const cache = new AnswerSemanticCache({ similarityThreshold: 0.8, openAI })
async function answerUser(question: string) {
let answer = await cache.getAnswer({ question })
if (answer === null) {
answer = await executeRAG({ question })
await cache.setAnswer({ question, answer })
}
return answer
}
async function main() {
await answerUser('Who is the future of educational LMS?')
await answerUser('Which company is the future educational LMS?')
}
main()Pour aller en production
Dans cet article, je présente rapidement le concept de cache sémantique et propose une implémentation en Typescript.
Cependant, dans un système de production il y a de nombreux points à prendre en considération
Utiliser un cache store distribué avec recherche sémantique
Votre base de données possède surement des fonctionnalités de recherche sémantique. Vous pouvez l’utiliser pour stocker les embedding des questions et les réponses de votre RAG:
Choix des réponses à mettre en cache
Dans une application faisant intervenir des LLMs, on sait que toutes les réponses ne sont pas de la même qualité.
Afin d’éviter de mettre en cache une réponse inadéquate, il est préférable de coupler le système de cache avec le système de feedback.
Ainsi, lors d’un feedback positif d’un utilisateur, la réponse sera mise en cache.
Ajustement du seuil de similarité
Chaque cas d’usage nécessitera des seuils différents, en général pour un RAG ils seront compris entre 0.7 et 0.8.
Afin d’affiner le seuil, je conseille de mettre en place un système de monitoring des cache hit/miss pour pouvoir faire de l’investigation à posteriori sur les valeurs à la limite du seuil et éventuellement adapter ce dernier.
Expiration de cache
La hantise des développeurs, il va falloir mettre en place une politique d’expiration en prenant en compte:
- le dimensionnement du cache store (votre DB à priori)
- la mise à jour des connaissances
- la mise à jour du RAG (retrieval, re-ranking, prompt, etc)
Conclusion
Le cache sémantique est une méthode utilisant les capacités des modèles de langue pour prendre en compte les variations du langage naturel n’impactant pas ou peu la sémantique.
Ce type de cache est utilisé principalement pour réduire la latence et les coûts inhérents aux systèmes utilisant des LLMs et n’ont donc pas les mêmes échelles de performances.
Un cache applicatif standard utilisant Redis est supposé fournir des réponses en quelques millisecondes au lieu de quelques centaines de millisecondes.
Un cache sémantique est beaucoup plus lent car il doit utiliser un modèle pour calculer le vecteur de champ sémantique avant de rechercher dans une base vectorielle.
Le processus complet peut prendre plusieurs centaines de millisecondes mais c’est toujours un gain conséquents face à une réponse d’un système LLM qui peut prendre plusieurs dizaines de secondes.

