gen-ai.fr
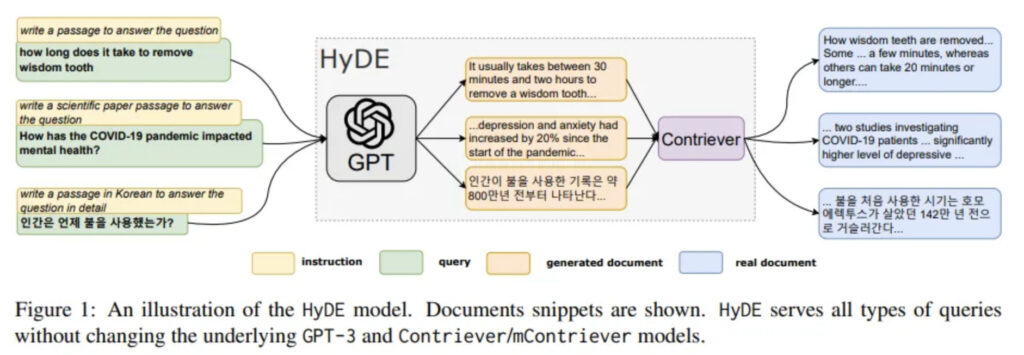
The vector search of a RAG consists of a semantic search in our documents.
The original request (the query) is particularly important because it will give us our vector used in the search for the nearest neighbors of the vector plane.
The documents that make up our vector database very often come from different sources and therefore have semantic fields that can be quite distant even if they concern the same thing.
It is in this context that the HyDE method comes into play to maximize the chances of recovering documents related to the original request.
Augmenting the semantic field
Each data source contains documents that were written by people with different skills and the vocabulary used is therefore also different.
To try to approximate the semantic fields of each data source, a hypothetical response to the request will be generated for each of them.
Of course this answer will be false but the semantic field used will make it possible to find documents close to the meaning of the original request.
Let's take an example to see it more clearly, imagine the following request made by a user of our RAG:
Is it possible to force a user to register for a training course upon first connection?In our document base, 2 data sources are ingested: Notion (product owners) and Github (developers).
For each data source, we will generate hypothetical answers to our query using the appropriate semantic field. Of course we use GPT-4 for this.
This is what the prompt might look like:
Here's a question from a user: "Is it possible to force a user to register for a training course upon first connection?"
Generates two hypothetical answers to this question:
- by putting yourself in the shoes of a developer
- by putting yourself in the shoes of a product ownerFor better performance, we must concatenate the request to each of the hypothetical responses generated.
The rest of the vector search is done as in a classic RAG.
Limits
Since hypothetical responses are being generated, the amount of "noise" will increase and may reduce the quality of the returned documents.
The RAG filtering function must take this into account so as not to pollute the final prompt with unnecessary documents.
Finally, latency will also be increased given the fact that one more call to an LLM must be made upstream of the RAG.
TAGS:


GenAI est un site français à propos des avancées technologiques dans le monde de l'intelligence artificielle.
© Copyright CC-BY-SA 2023-2024 gen-ai.fr