Stable Diffusion est un modèle communautaire propulsé par l’entreprise StabilityAI depuis Août 2022.
La dernière version date de Juillet 2023, il s’agit du modèle SDXL qui créé des images de très haute qualité. Nous parlerons exclusivement de cette version.
- Éditeur 👉 StabilityAI
- Modèle 👉 Stable Diffusion XL
- Date de sortie 👉 Juillet 2023
- Interface 👉 application web + application de bureau + API
- Coût 👉 10$ pour 5000 images chez StabilityAI (ou gratuit sur son ordinateur)
https://platform.stability.ai/
Utilisation dans l’application web
Après avoir créer un compte sur StabilityAI et avoir acheté des crédits, il est possible d’accéder à l’interface de création via https://platform.stability.ai/sandbox.
StabilityAI offre toutes les possibilités de génération d’image:
Utilisation dans l’application de bureau
Une carte graphique puissante (4Go de RAM dédiée minimum) est nécessaire pour utiliser StableDiffusion directement sur son ordinateur.
L’installation fonctionne sur Windows, Mac et Linux mais n’est pas à la portée des néophytes.
Un tutoriel est disponible sur Github pour Stable Diffusion UI ou en français sur le blog StableDiffusion.
Utilisation via API
Il est possible d’utiliser StableDiffusion depuis des programmes en utilisant leur API.
La documentation est disponible en ligne StabilityAI API Documentation
Un SDK Python est également disponible (le SDK Typescript gRPC est déconseillé car très compliqué à installer et utiliser)
Contrôler le style des images générées
Les images générées par StableDiffusion sont de styles très différents. En spécifiant la même seed, il est possible de conserver le même style entre deux images mais en revanche il est assez dur de contrôler finement le style des images en amont.
Il existe heureusement des méthodes pour avoir plus de contrôle sur les images générées.
ControlNet
ControlNet est un autre réseau de neurones utilisé pour contrôler les générations faites par StableDiffusion.
Il repose principalement sur le principe de « canny » qui sont des sortes d’empreintes d’images qui sont ensuite utilisées avec StableDiffusion pour contrôler la génération.
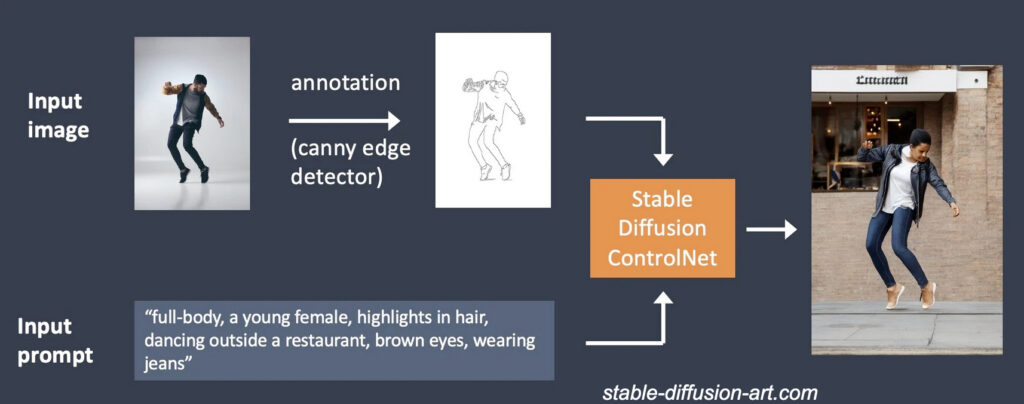
Quelques usages:
- Spécifier une pose particulière
- Générer des images au style similaire
- Transformer un dessin à main levé en image photoréaliste
C’est par exemple de cette manière que scenario.com génère du matériel visuel pour le monde du jeu vidéo.
Un tutoriel très complet est disponible sur Stable Diffusion Art.
En général ce genre de manipulation avancée est assez compliqué à réaliser si vous n’avez pas de connaissances en informatique.
LoRA
Un modèle LoRA est un sous modèle StableDiffusion ayant été entrainé sur un ensemble d’images.
Ce genre de modèle est ensuite capable de générer des images toutes dans le même style que les images d’entrainement.
C’est utilisé pour conserver un même style dans toutes les images généré, quelques usages:
- Illustrations d’un livre, d’une bande dessinée
- Générer ses propres avatars numériques à partir de photo de soi
Tout comme ControlNet, ce genre de manipulation est assez compliqué à réalisé entre les connaissances en informatique et la puissance de calcul nécessaire à entrainer le modèle.
Des instructions et des scripts pour StableDiffusion XL sont disponibles sur Github.
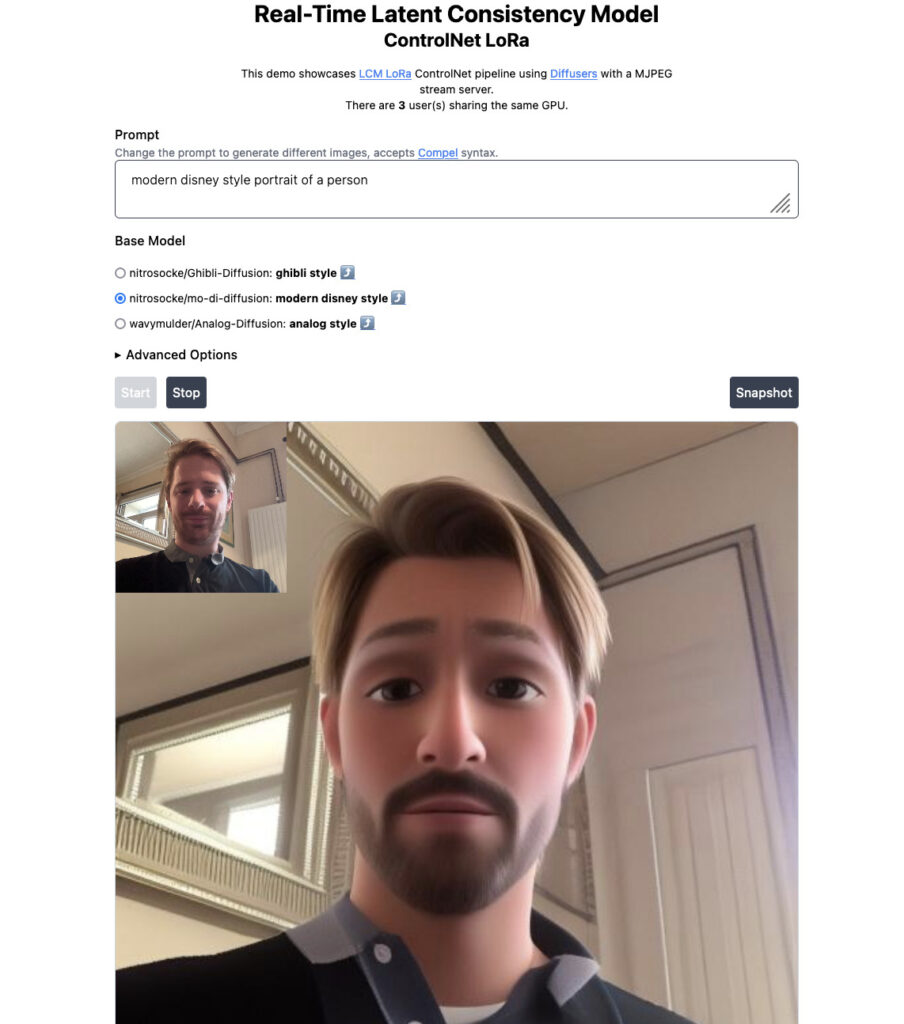
Génération en temps réel avec LCM LoRA
La technique Latent Consistency Model (LCM) appliquée aux modèles LoRA permettent de diffuser en temps réel une image transformée par le modèle.
Le flux vidéo d’une webcam peut être capté puis injecté dans le modèle afin d’être restitué dans le style du LoRA que l’on a entrainé.
Concrètement cette technique est possible en réduisant le nombre d’étapes nécessaire à la génération de l’image (en moyenne 4 contre un minimum de 25 habituellement)
Une démo est disponible gratuitement chez Hugging Face