Auteur/autrice : Adrien Maret
-

Chaine de pensée, le couteau suisse du Prompt Engineer
Une des techniques les plus efficace pour améliorer la performance d’un prompt est la Chaine de pensée (Chain of Thought ou CoT). Cette technique peut s’appliquer dans toutes les situations du LLM Engineering: Pour bien comprendre le fonctionnement de la Chaine de pensée et comment l’utiliser, il est nécessaire de comprendre le fonctionnement interne d’un…
-

Modifier efficacement un texte avec un Agent LLM
Les LLMs sont très pratiques pour manipuler du langage naturel. On peut par exemple leur demander de mettre à jour un document à partir d’une nouvelle information disponible. Le problème de cette démarche, c’est que pour un document de 50 lignes avec une modification sur seulement quelques lignes, le LLM va nous renvoyer l’intégralité du…
-

A l’intérieur des LLMs: comprendre les tokens
Quand on parle de LLMs, on se retrouve face à des concepts qui ne sont pas toujours forcément compris. Après tout, on peut très bien se servir de GPT-4 sans comprendre ce que sont les tokens ou la température. Cependant, lorsque l’on cherche à aller plus loin dans l’utilisation, il est nécessaire de comprendre ces…
-

Comprendre les implications de l’IA Act pour les produits GenAI
C’est officiel depuis le 13 mars 2024: l’IA Act est à présent en application. L’IA Act c’est un peu le RGPD de l’IA. C’est à dire un ensemble de règles définies par le législateur pour encadrer l’utilisation de l’IA sur le territoire européen. Cette nouvelle régulation est dans les cartons depuis 2021. Elle a bien…
-

Bases de données vectorielles: chronique d’une mort annoncée
Depuis déjà quelques mois, on entend beaucoup parler de ces nouvelles « Vector Database » qui seraient la « mémoire » des Large-Language-Models. Pinecone (128M$), Qdrant (28M$), Croma (18M$), il y a plusieurs dizaines de startups qui lèvent des millions et se battent dans le marché hypothétique de la recherche vectorielle. Dans cet article, nous verrons en quoi les…
-

La véritable révolution apportée par le modèle Gemini de Google
Ceux qui font couler de l’encre sur l’authenticité de la vidéo de Google sur les performances multimodales de Gemini ou ses performances par rapport à GPT4 passent à côté de la véritable révolution des annonces de Google. Le marché est aujourd’hui dominé par des gros (très gros) LLM. De Mistral à GPT4, en passant par…
-

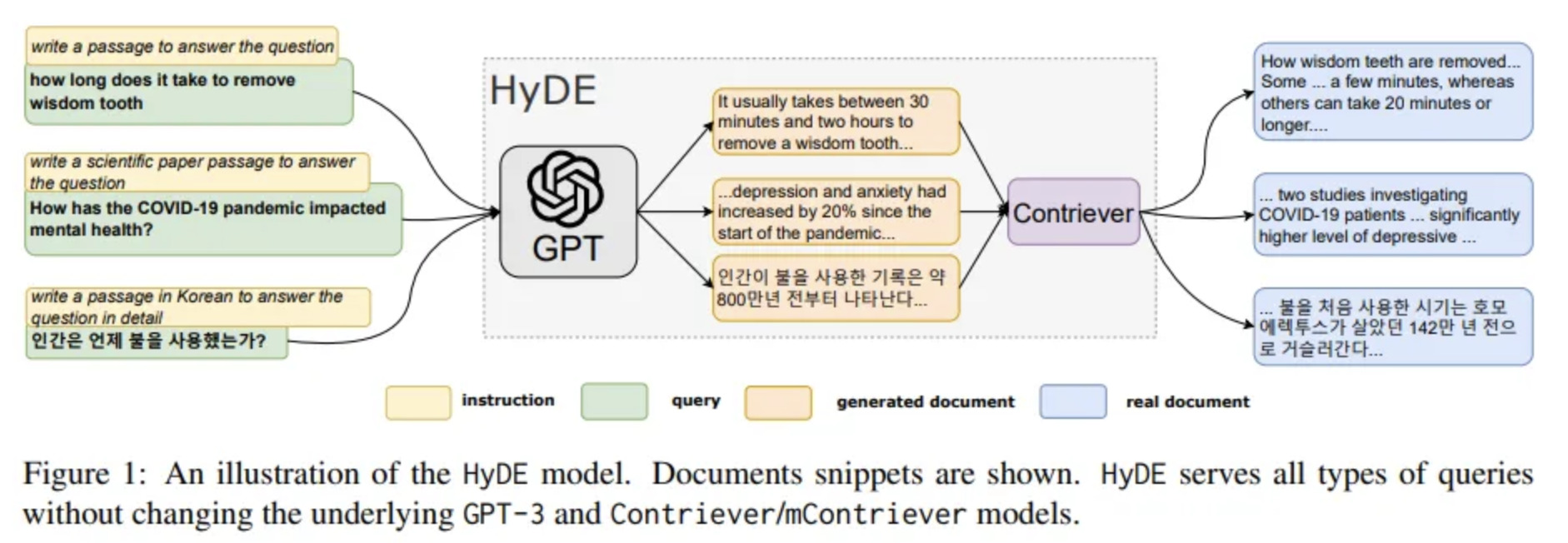
Un RAG avec la méthode HyDE : Intégration de document hypothétiques
La recherche vectorielle d’un RAG consiste en une recherche sémantique dans nos documents. La demande d’origine (la requête) est particulièrement importante car elle va nous donner notre vecteur utilisé dans la recherche des plus proches voisins du plan vectoriel. Les documents qui composent notre base de données vectorielle sont très souvent issus de sources différentes…
-
Impact de la langue sur les performances des LLM
Les Large-Language-Models ont été entrainés en majorité sur des textes en anglais et donc leurs capacités de raisonnement sont meilleures lorsque les instructions sont données dans cette langue. Pour obtenir de meilleures performances, il est préférable d’écrire les prompts exclusivement en anglais. Lorsque les réponses doivent être en français alors il est possible d’écrire un…
-
Google entre dans la dance GenAI avec Lyria de Deepmind
Depuis le début de l’année on pouvait penser que Google (Alphabet) était en retard dans les innovation autour des IA génératives avec l’avance énorme de Microsoft via OpenAI et Meta avec le modèle LlaMa 2. C’est donc dans le domaine de la génération musicale que Google frappe un grand coup en présentant son nouveau modèle:…
-
Spécialisez vos Agents LLM pour de meilleures performances
Très loin de la hype autour des AutoGPT et autres expériences autour des « AGI » (Artificial General Intelligence), cela reste très compliqué pour GPT-4 de construire une réflexion poussée sur une tâche à résoudre sans lui fournir les instructions et actions adéquates. (Les développeurs de BeeBot ont même jeté l’éponge) Il faut considérer un Agent LLM…