One of the most effective techniques for improving the performance of a prompt is Chain of Thought (CoT).
This technique can be applied in all LLM Engineering situations:
- Content generation
- Creating structured entities
- Agent Workflow
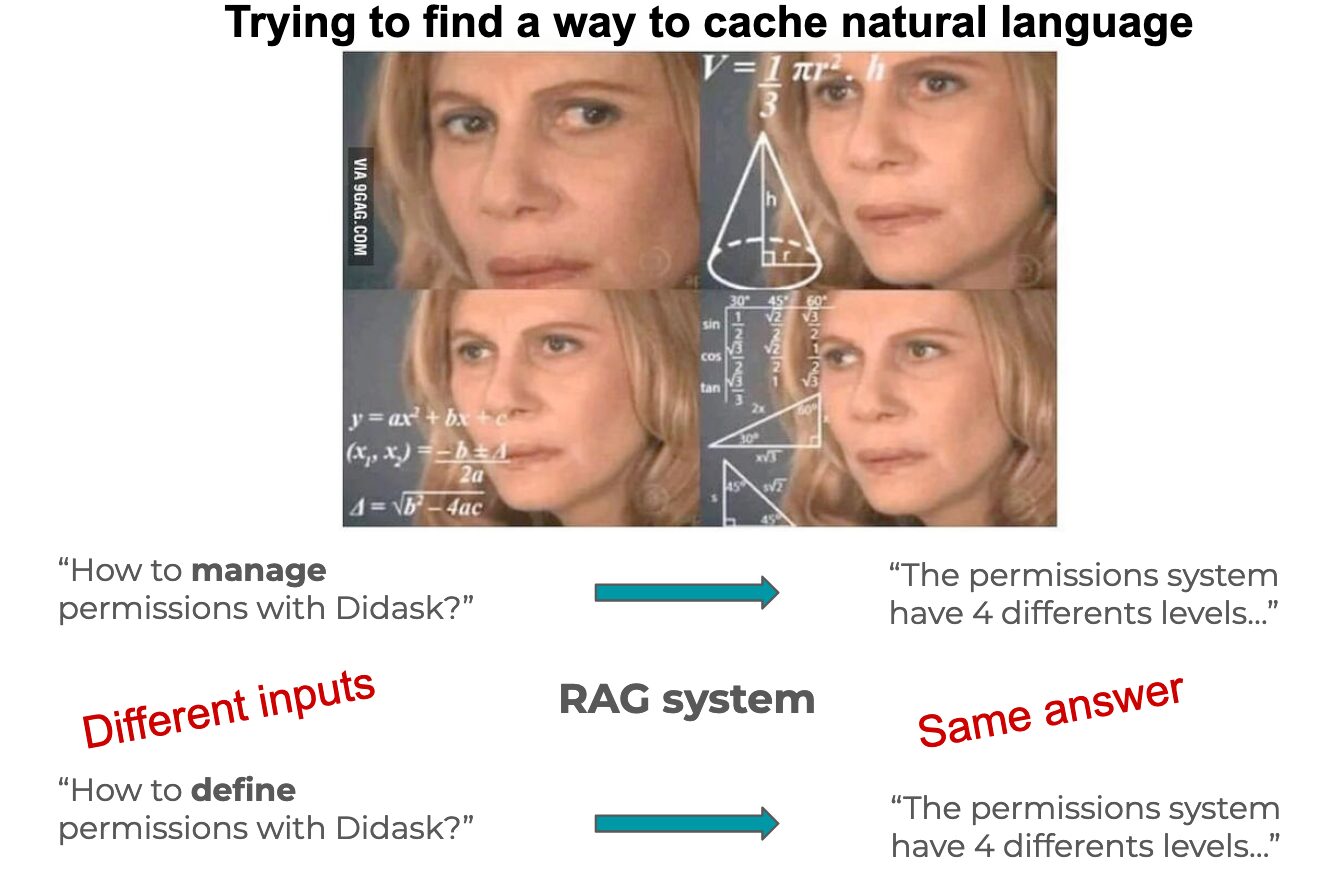
- RAG Generation Step
- Facet extraction
- and many others!
To fully understand how the Chain of Thought works and how to use it, it is necessary to understand the internal workings of an LLM during the inference (generation) process.
How the Chain of Thought works
As is often the case with LLMs, we can make an analogy with human reasoning.
To better resolve a problem, we can, for example, divide it into several tasks or summarize all the data available upstream.
This allows us to better structure our thinking to solve the problem.
The Chain of Thought is a relatively similar technique which exploits the probabilistic capabilities of LLMs in order to reinforce the semantic field of what we wish to generate.
Concretely, most of the time this consists of generating intermediate steps or giving examples to the LLM to better guide the generation of the final answer.
Inference loop
To fully understand the underlying mechanisms of the Chain of Thought, you must understand how inference (generation) works.
Inference is the process in which a prompt is provided to an LLM and a response is provided to the user.
During inference, all the tokens from the prompt are passed to the LLM which will then propose the token with the most probability of appearing.
Then the entire prompt + this new token are passed again to the LLM which offers the next token and so on.
This process is repeated until the LLM offers a special token that indicates the end of the generation. At this point, rather than restarting an inference cycle, the result is returned to the user of the model.
This means that the tokens generated by the LLM are also taken into account in the generation and this is the explanation of the Chain of Thought mechanism.
A Prompt Engineer can therefore use two levers when thinking about his inference:
- The text of the initial prompt
- Intermediate generation stages
4 concret examples to understand
Let’s now move on to practice with 4 uses of the Chain of Thought in concrete cases rather than “Hello World Foobar” themselves generated by an LLM to do SEO.
Each example presents a concrete use case of LLM Engineering and is accompanied by a generation example with GPT-4o.
Content generation
One of the recurring use cases of LLMs is the generation of a summary.
Rather than directly asking the LLM to generate a summary, we can first ask it to generate a table of contents and then a summary.
This will emphasize the chapters to be summarized as they will be listed in the intermediate generation steps.
The final result will therefore be more likely to be exhaustive of the content of the initial document.
You are excellent at summarizing documents
I will give you the content of a document and you will have two tasks:
- Start by writing the table of contents for this document, including all levels of headings
- Finish by writing a summary of the content of the document using the table of contents
# Begin Document
{{ document }}
# End Document
In this example, the Chain of Thought technique allows us to extract information from the text (the table of contents) in order to guide the final generation.
Example of Content Generation with Chain of Thought
Creating structured entities
The Chain of Thougts is also very useful for controlling the format for generating structured entities.
Here we can directly give the LLM examples of the expected response format:
You are an excellent teacher capable of creating quality lessons.
From the following document, extract the key messages as well as the
expected changes.
# Begin Document
{{ document }}
# End Document
Uses the following YAML format to respond:
```yaml
granules:
- keyMessage: “a key message”
desiredChange: “expected change when the learner understands the key message”
- keyMessage: “another key message”
desiredChange: “expected change when the learner understands the key message”
```
Example of Creating structured entities with Chain of Thought
LLM Agent
In the operation of an LLM Agent, it is preferable to ask the LLM to explicitly generate a plan of actions that it must carry out to accomplish its task.
You are a semi-autonomous Agent capable of using tools to accomplish a task. Your task is to reserve a meeting slot for the following people: - Adrien - Hubert You can use the following tools: - listMeetings(name: string): lists a person's upcoming meetings - bookMeeting(nameA: string, nameB: string, time: Date): books a meeting Start by making a plan of the actions you will have to carry out to solve your task. Then respond with the tools you want to use in a YAML block, example: ```yaml tools: - name: listMeetings arguments: [“Aschen”] ```
From this prompt, the LLM should start by giving the list of actions that he considers necessary to use and this will allow him to use the tools provided wisely.
Example of LLM Agent with Chain of Thought
RAG generation step
In a RAG (Retrieval Augmented Generation) use case, the use of the Chain of Thought can improve the quality of the response generated while reducing hallucinations.
The challenge of this step is to make the LLM use the content of the documents found to answer the question.
We can therefore start by asking the LLM to summarize the relevant information contained in the documents:
You need to answer the following question from a user: {{ userQuestion }}
You need to use the content of the following documents to answer:
# Begin Documents
{{ documents }}
# End Documents
Start by listing the information from each document that is relevant to answering the user's question.
Then, use this information to generate a direct answer to the user's question.
Use the following YAML format to answer:
```yaml
information:
- “excerpt from a document that is relevant to the question”
- “another excerpt from a document”
- “use as many excerpts from the document as needed”
finalAnswer: “final answer to the user's question using information from the documents”
```
The step of extracting information deemed relevant will allow the LLM to reinforce this semantic field when it has to generate the final response because all the previously generated tokens will also be used.
Example of RAG generation step with Chain of Thought
Conclusion
Chain of Thought is a very effective technique for improving prompt performance.
It makes it possible to reinforce the semantic field of the expected result in two different ways:
- Explicit Chain of Thought: giving examples of the expected result in the prompt
- Internal Chain of Thought: by instructing the LLM to generate intermediate “reasoning” steps
The second technique is particularly effective because it allows you to use the capabilities of the LLM to extract information that it can itself use during the final generation step!
Finally, the Chain of Thought can be used within the same prompt but can also be split into a Prompt Chain in order to further improve performance.
Of course, this increases latency and costs but in many situations the result is worth the investment 😉