gen-ai.fr

For several months now, we have heard a lot about these new "Vector Databases" which would be the "memory" of Large-Language-Models.
Pinecone ($128M), Qdrant ($28M), Croma ($18M), there are several dozen startups raising millions and fighting in the hypothetical vector search market.
In this article, we'll look at how vector databases are more of a feature than a full-fledged product and why they're already outdated.
What is vector search?
Transformer type AI models used by LLMs (but also for the generation of images, sounds, etc.) have an internal representation of the semantic field of a text in the form of a vector.
This semantic field represents the "meaning" of the text and it is represented in the form of an N-dimensional vector which is also called Embedding.
For example, for OpenAI's text-embedding-3-small model, the vector has 1536 dimensions. It is therefore an array of 1536 numbers between -1 and 1.
What is practical about vectors is that we know how to manipulate them very well. Most of the time, we manipulate vectors in 2 or 3 dimensions but mathematical operations can also be applied to vectors of 1536 dimensions.
For example, there are methods for calculating the distance between two vectors. In the case of an embedding from an LLM, this will indicate the proximity of the semantic fields.
If we summarize, vector search is quite simply semantic search.
Well, on the other hand, we have to be honest, it is by far the best semantic search technique that we have had until now, but ultimately it simply remains the last iteration of this research field.
Vector Search and LLMs usecase
One of the most common uses of LLMs is Retrieval Augmented Generation, which consists of overcoming the main drawback of LLMs, that is to say a prohibitive re-training cost on recent or private data.
Appropriate re-training would allow the model to ingest new knowledge but the GPU time cost forces most actors to use a RAG pattern instead.
The first step of RAG consists of retrieving documents likely to contain the answer to a question asked by a user.
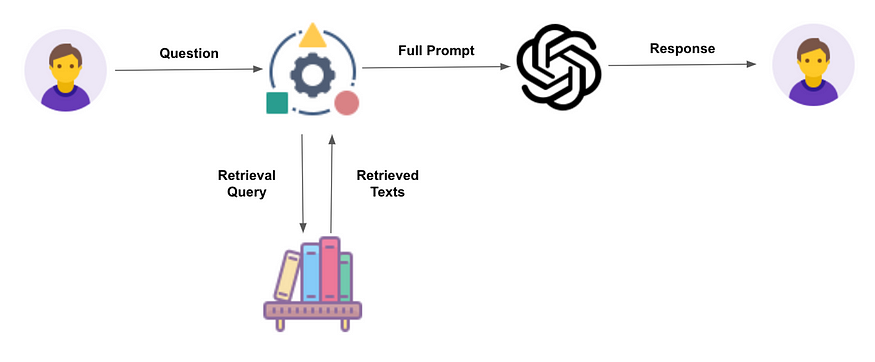
This is where vector search comes in. This type of semantic search will make it possible to find relevant documents in a documentary database such as the internal documentation of a company for example.
(See also A RAG with the HyDE method: Integration of hypothetical documents)
Once the documents relevant to a question are retrieved, they will be injected into a prompt with the question to allow the LLM to provide a specific answer in natural language.
Building a real search engine
Vector search offers good results for retrieving relevant documents but it is far from sufficient
In the real world, documents also have metadata that will influence the retrieval process.
Example: title, author, permission group, source, document type, etc.
Permissions and filtering
The first concrete example is permission management. In most companies, access to information is compartmentalized for reasons of confidentiality and security.
It is then unthinkable that the RAG could happily dig into confidential documents reserved for C levels to answer a question asked by a trainee.
A filtering step is then essential to exclude documents to which we do not have access from the results and prevent them from ending up in the response generation prompt.
The vector databases on the market have understood this well and we see this type of functionality appearing at Pinecone and Qdrant for example.
Scoring
Those who have already had to build a search engine know that not all search conditions are equal.
In an advanced example, we could decide to store the document title embeddings in addition to those representing the content.
Example of a question: How to use Didask's educational AI?
Let's then imagine two documents
- Create granules with Didask AI: a document explaining how educational AI works
- Comparison of educational AI: a document citing the different educational AI on the market as well as that of Didask
The content of both documents will be semantically close to the question but if we consider the semantic content of the titles, then that of document 1 is much closer.
In a real search engine, documents each have a score assigned based on the query and one can naturally configure a greater importance for the title than for the content and adjust the score accordingly.
For example in Elasticsearch this is done using the boost keyword which allows the score to be weighted according to a sub-part of the query as in our example.
Query Language
Beyond vector search, we may want to apply scoring functions for a whole range of use cases.
For example, it is possible to assign a higher score to more recent documents or to documents that have been referenced many times within other documents.
In addition to vector search, we can also use simpler techniques such as keyword search to once again give an additional boost to documents containing the desired keywords.
Finally, the combination of operators with "AND" and "OR" is necessary to construct complete queries.
Search Engine at scale with Elasticsearch
When we talk about search engines, it is difficult to ignore the undisputed leader in the field: Elasticsearch.
Like all vector databases, Elasticsearch supports vector type fields and proximity queries (knn or nearest neighbors) allowing the adjacent semantic fields of LLM embedding to be highlighted.
Elasticsearch supports scoring and also a whole range of queries.
Performances
Regarding performance, specialized vector databases are not even necessarily the most efficient.
In a benchmark of the vector search functionality of Postgres vs Pinecone, Postgres significantly outperforms Pinecone for an equivalent infrastructure cost.
For its part, Elasticsearch is a horizontal scalability model with clusters reaching up to 600 Petabytes and several million requests per day in some cases.
Industry standard
Choosing a product to include in your infrastructure is not a decision to take lightly.
Several factors must be taken into account, such as the richness of the ecosystem in terms of SDKs, documentation and host offering the product off the shelf or the sustainability of the company developing the product.
Today, startups building their entire business model on a simple functionality are not sure that they will still exist in 5 years while your business will still exist (at least I hope so).
Conclusion
Vector databases are built around the sole functionality of semantic search, whereas the creation of a search engine requires going much further.
Almost all databases on the market already have their semantic search functionality built-in:
- Elasticsearch with knn
- Postgres with pg_vector
- Mongo with Atlas Vector Search (only available in the cloud)
Moreover, the real challenges of a database often lie elsewhere than in a simple vector search.
Query planner, cluster scalability, data integrity, the real challenges are still to be met for new vector databases while existing databases have long proven themselves
In a future series of articles, I will explain how to use Elasticsearch and GPT4 to create a real knowledge engine, stay tuned 😉
TAGS:


GenAI est un site français à propos des avancées technologiques dans le monde de l'intelligence artificielle.
© Copyright CC-BY-SA 2023-2024 gen-ai.fr