Despite their multi-modal capabilities, LLMs work best when fed with text.
For humans, the standard digital document is a PDF with text, tables and images. It is therefore necessary to extract the content of a PDF and then provide it to an LLM.
PDF being what it is (horribly complicated), most modern techniques use a mix of text extraction, images and character recognition (OCR).
In this article, we will study two solutions for extracting text and images from a PDF document:
- a cloud solution: Reducto
- a self-hosted solution: Marker
Extract and split PDF with Reducto
Reducto offers a SaaS API to ingest PDF documents and extract text and images.
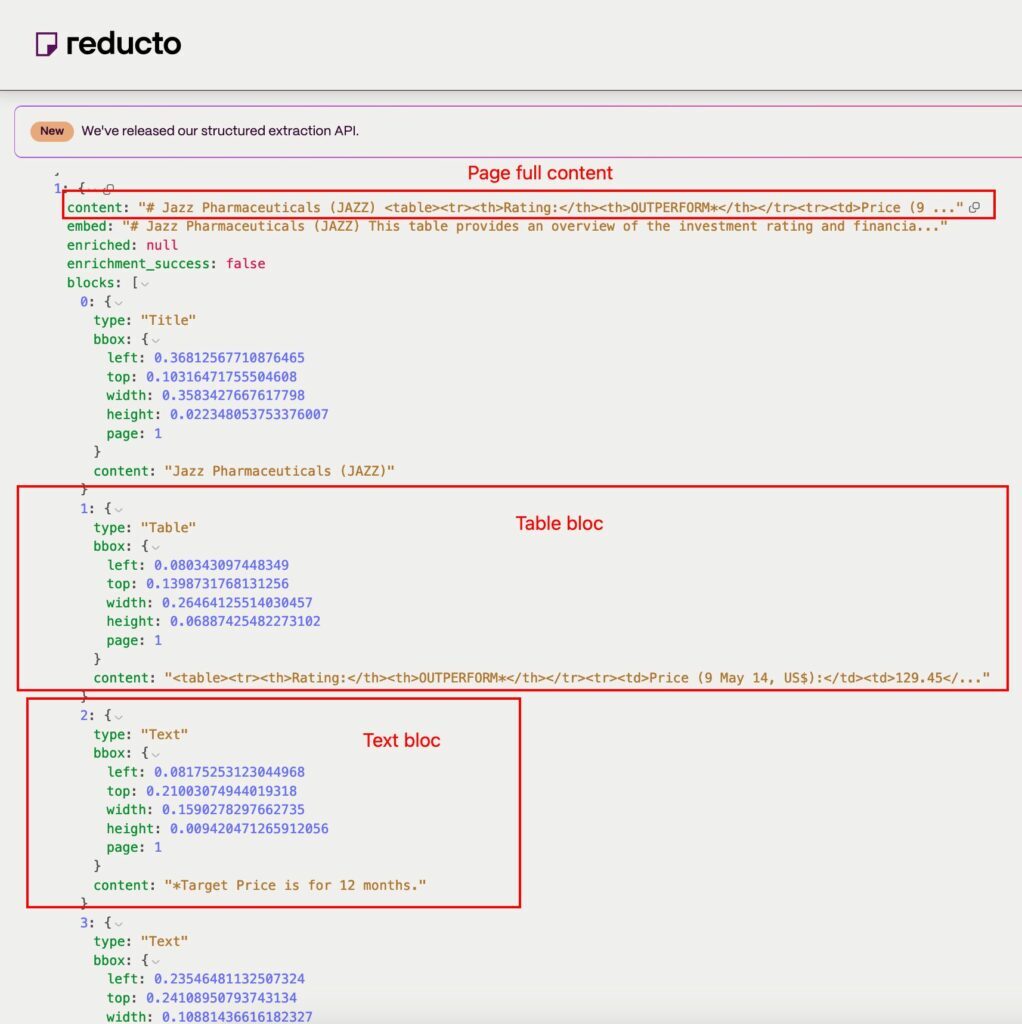
For each page, we will be able to retrieve the raw text content with a bonus description of the images and tables.
We can also retrieve the list of elements of each page (text, image, table, etc.) with their content and position on the page.
See an example of an analyzed document
Reducto also offers to take care of the chunking to then facilitate the use of data in a RAG type system.
Pros:
- Easy-to-use SaaS API
- Extraction, description and positioning of PDF elements
- Chunking for RAG
Cons:
- No pay-as-you-go (minimum $300/month, $0.02 per page)
- SaaS API (data sovereignty issue)
- Extracted images hosted by them
- Self-hosting on the enterprise plan only (>$2000/month)
Extracting Text and Images from PDF with Marker
Marker is a tool for recognizing and extracting information from a PDF document.
They use their own PDF recognition models to recognize the different elements of a PDF (table, images, text, etc.) as well as an OCR model (Surya).
License
Marker is licensed under GPL but the model weights are licensed under cc-by-nc-sa-4.0 which excludes commercial uses. You must purchase an On Premise license from Datalab, the company that publishes Marker, to use it on your own servers.
However, for personal use, for research or if your company has a turnover of less than 5 million or has raised less than 5 million dollars, then using Marker is free.
Usage
To use Marker, you must first install Python3 and Torch (machine learning framework).
For a Mac (M3):
# Create working dir
mkdir marker-pdf && cd marker-pdf
# Install virtual env
python3 -m venv venv
# Initialize virtual env
source venv/bin/activate
# Install pytorch
pip3 install --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/cpu
# Install marker pdf
pip3 install marker-pdfHere is an example script to convert the PDF to markdown format and save the images.
We will use this example PDF from a textbook.
The first time the code runs, it will download the weights of all the models used (~2 GB in total).
from marker.convert import convert_single_pdf
from marker.models import load_all_models
import os
fpath = "./somatosensory.pdf"
model_lst = load_all_models()
full_text, images, metadata = convert_single_pdf(fpath, model_lst)
# Create images directory if it doesn't exist
os.makedirs("images", exist_ok=True)
# Save images and create markdown content
md_content = []
# Add extracted text
md_content.append(full_text + "\n\n")
# Create doc directory if it doesn't exist
os.makedirs("doc", exist_ok=True)
# Save and link images
for image_name, image_obj in images.items():
# Save image to the images directory
image_path = os.path.join("doc", image_name)
image_obj.save(image_path)
# Write markdown file
with open("doc/result.md", "w", encoding="utf-8") as f:
f.writelines(md_content)
Here is the result of the generated markdown and the extracted images:
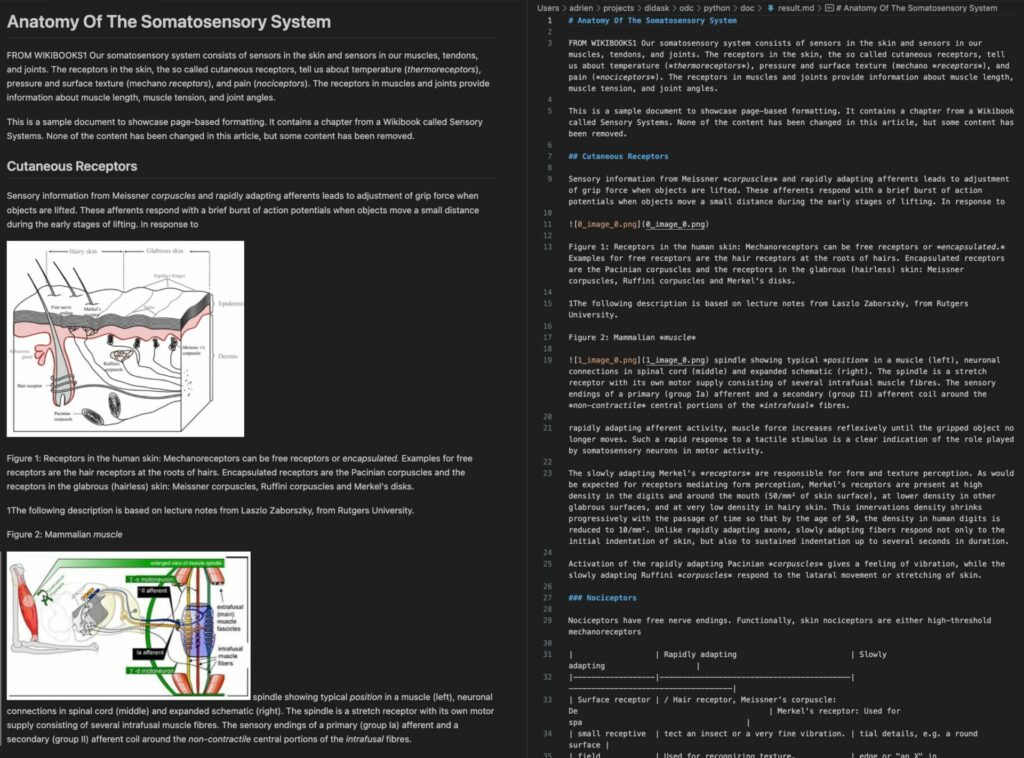
It is then possible to apply additional processing to the markdown:
- description of images using a Vision model
- splitting the text into chapters using titles
This data is then ready to be used by the RAG ingestion pipeline.
Pros:
- Advanced element extraction with specialized templates
- Available in cloud or self-hosted version
- Data sovereignty in self-hosted version
Cons:
- No built-in slicing
- Only one paid plan at $5000 ($0.0025 per page)
- Potentially expensive self-hosted license (>$5000)
Other solutions
- Cloud or self-hosted
- Pay-as-you-go ($0.05 or $0.01 per page)
- self-hosted
- separate extraction of text and images
Convert PDF to image and extract information using a Vision model like GPT-4o.
Conclusion
Whatever the solution chosen, the results will not be perfect and some information may be extracted incorrectly.
PDF extraction and cutting is a fast-moving field and it is better to allow yourself to experiment with several tools before making a significant investment such as paying for and deploying a self-hosted version of a tool.