In a traditional algorithmic system, caching allows storing the result of a computation to reuse it later.
Typically, the result of a costly operation is saved to be served directly in the future.
The value used to retrieve the result of an operation is generally called a “key.”
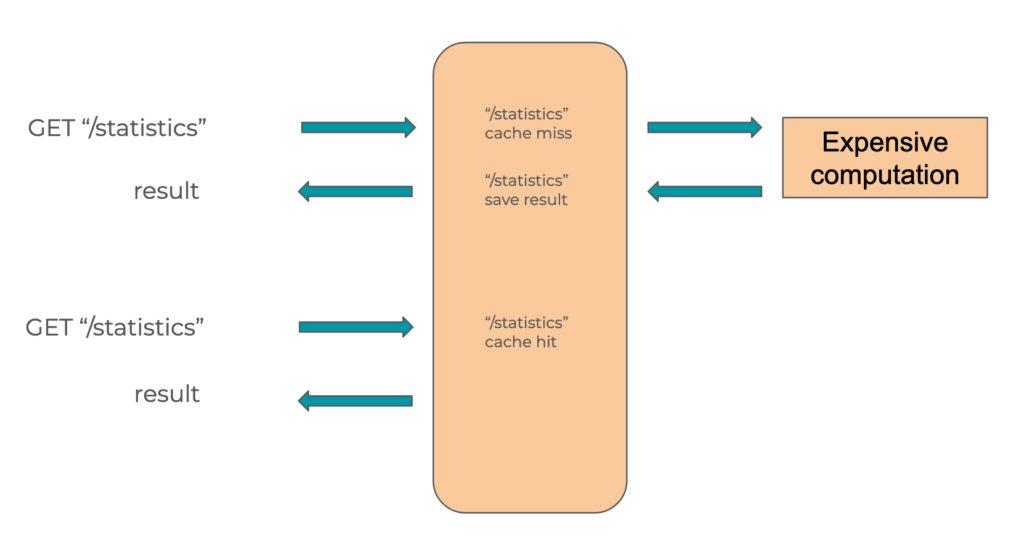
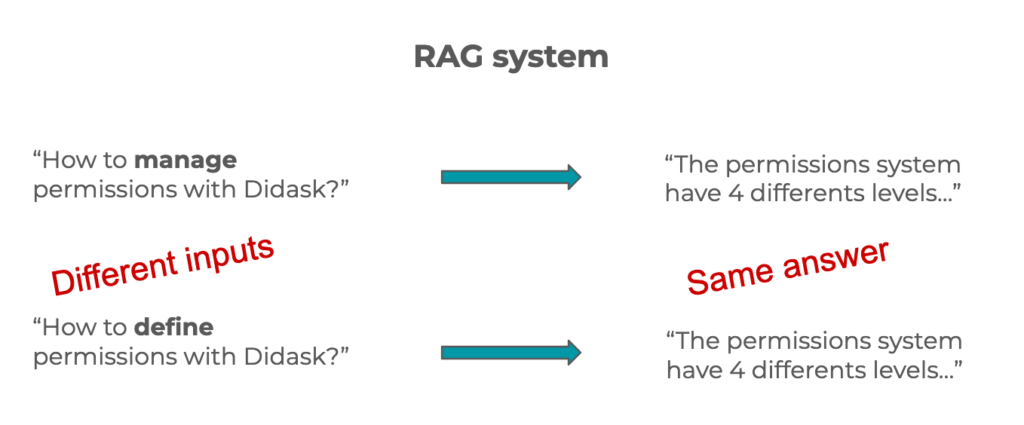
If we want to replicate this system with a RAG, we must account for the semantic flexibility of natural language.
A question can be phrased in several different ways while having the same meaning, and therefore the same answer.
We therefore need a system capable of understanding the nuances of natural language!
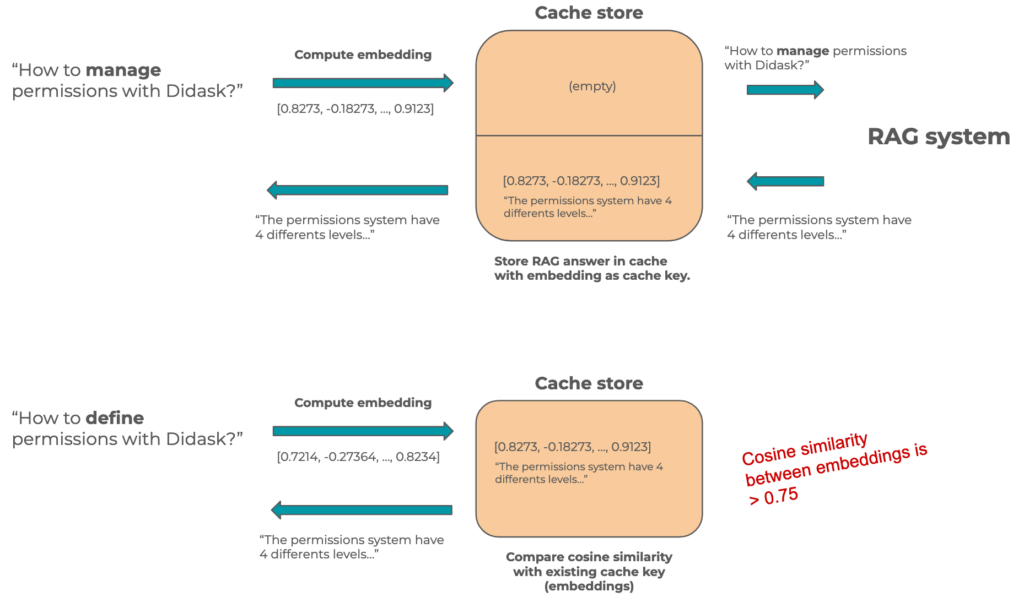
Semantic field vector as a cache key
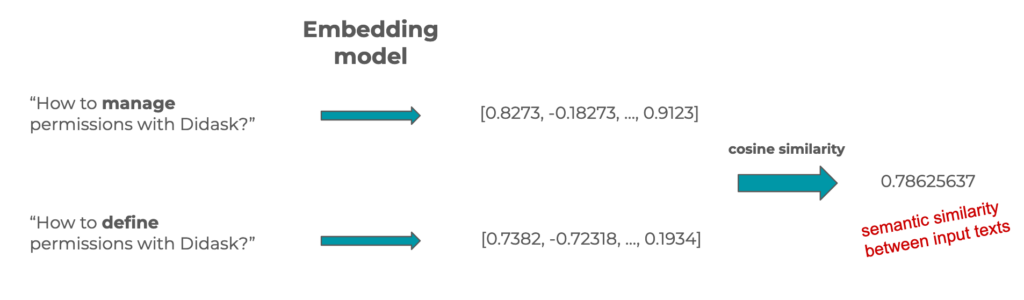
Semantic field vectors, or embeddings, are arrays of numbers that represent the meaning of a text.
Since they are vectors, they can be compared, and a number representing the distance between two vectors can be obtained using cosine similarity.
This number therefore also represents the semantic similarity (or meaning similarity) between two texts. This type of technique is widely used in vector databases.
In a semantic cache for a Retrieval Augmented Generation system, the semantic field vector of the question will be used as the cache key, and the RAG’s response will be the associated value.
When a new natural language request is received, the system will check if any semantic field vector in the cache is sufficiently similar to that of the request.
If so, the response stored in the cache can be returned directly.
“Talk is cheap, show me the code”
To implement a simple semantic cache in Node.js, I will need three things:
- An embedding model (we’ll use OpenAI’s text-embedding-3-small).
- A function to calculate cosine similarity.
- An in-memory cache store (LRUCache).
I will start by initializing a class with a createEmbeddings method to request embeddings for a text from OpenAI.
I will also set up my LRUCache instance with embeddings as keys and the response as values.
import { LRUCache } from 'lru-cache'
import OpenAI from 'openai'
const similarity: (
x: number[],
y: number[]
) => number = require('compute-cosine-similarity')
class AnswerSemanticCache {
/**
* LRUCache<questionEmbeddings, answer>
*/
private cache = new LRUCache<number[], string>({ max: 100 })
private similarityThreshold: number
private openAI: OpenAI
constructor({
similarityThreshold,
openAI,
}: {
similarityThreshold: number
openAI: OpenAI
}) {
this.similarityThreshold = similarityThreshold
this.openAI = openAI
}
private async createEmbeddings({ text }: { text: string }) {
const response = await this.openAI.embeddings.create({
input: text,
model: 'text-embedding-3-small',
})
return response.data[0].embedding
}
}I then need a setAnswer method to save an <embedding, response> pair in my cache:
class AnswerSemanticCache {
/**
* LRUCache<questionEmbeddings, answer>
*/
private cache = new LRUCache<number[], string>({ max: 100 })
// [...]
async setAnswer({ question, answer }: { question: string; answer: string }) {
const questionEmbeddings = await this.createEmbeddings({ text: question })
console.info(`Save answer for "${question}"`)
this.cache.set(questionEmbeddings, answer)
}
// [...]
}Finally, the getAnswer method will iterate over each element in the cache, calculate the cosine similarity, and compare it with the similarity threshold.
class AnswerSemanticCache {
/**
* LRUCache<questionEmbeddings, answer>
*/
private cache = new LRUCache<number[], string>({ max: 100 })
// [...]
async getAnswer({ question }: { question: string }) {
const embeddings = await this.createEmbeddings({ text: question })
for (const [questionEmbeddings, answer] of this.cache.entries()) {
const sim = similarity(embeddings, questionEmbeddings)
if (sim > this.similarityThreshold) {
console.info(`Cache hit for "${question}"`)
return answer
}
}
return null
}
// [...]
}We then wrap everything to properly execute our cache (executeRAG represents the function that requests a response from your RAG):
const openAI = new OpenAI({ apiKey: process.env.OPENAI_API_KEY })
const cache = new AnswerSemanticCache({ similarityThreshold: 0.8, openAI })
async function answerUser(question: string) {
let answer = await cache.getAnswer({ question })
if (answer === null) {
answer = await executeRAG({ question })
await cache.setAnswer({ question, answer })
}
return answer
}
async function main() {
await answerUser('Who is the future of educational LMS?')
await answerUser('Which company is the future educational LMS?')
}
main()For production use
In this article, I briefly introduce the concept of semantic caching and propose an implementation in TypeScript.
However, in a production system, there are many factors to consider.
Using a Distributed Cache Store with Semantic Search
Your database likely has semantic search capabilities. You can use it to store question embeddings and your RAG’s responses:
Choosing Responses to Cache
In applications involving LLMs, not all responses are of the same quality.
To avoid caching inadequate responses, it’s best to couple the cache system with a feedback system.
For instance, when a user provides positive feedback, the response can be cached.
Adjusting the Similarity Threshold
Every use case requires different thresholds; generally, for a RAG, they range between 0.7 and 0.8.
To refine the threshold, I recommend implementing a monitoring system for cache hits/misses. This allows post-investigation of values close to the threshold, enabling you to adjust it accordingly.
Cache Expiration
The eternal challenge for developers: setting up an expiration policy, considering:
- Cache store sizing (likely your database)
- Knowledge updates
- Updates to the RAG (retrieval, re-ranking, prompt, etc.)
Conclusion
Semantic caching leverages the capabilities of language models to account for natural language variations that do not significantly affect semantics.
This type of cache is primarily used to reduce latency and costs associated with LLM-based systems, and thus operates at a different performance scale.
A standard application cache using Redis is expected to provide responses in a few milliseconds, compared to hundreds of milliseconds.
Semantic caching is slower since it must use a model to compute the semantic field vector before searching in a vector database.
The entire process can take several hundred milliseconds but still represents a significant improvement compared to LLM system responses, which can take several seconds.


