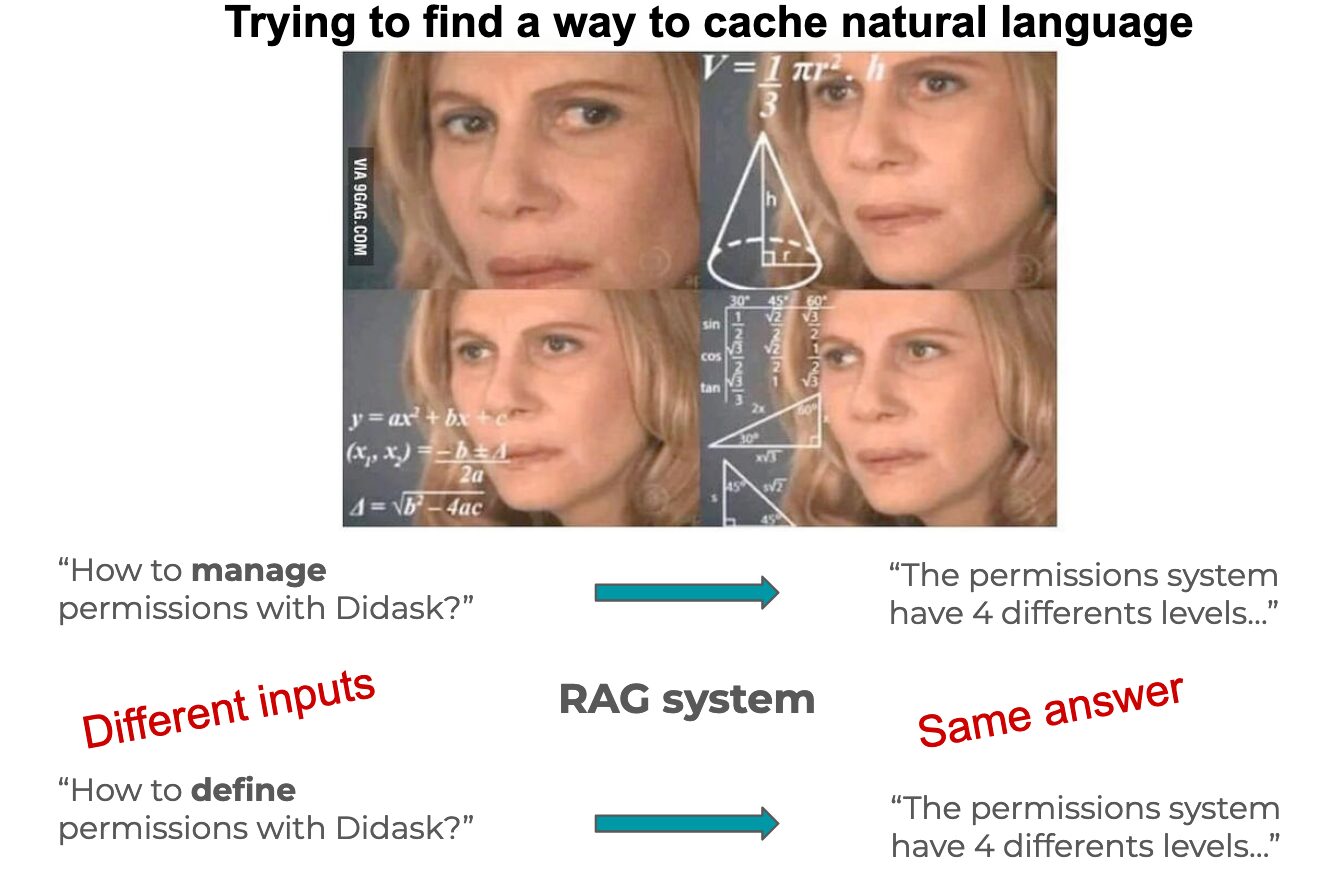
When we talk about LLMs, we find ourselves faced with concepts that are not always necessarily understood.
After all, you can use GPT-4 very well without understanding what tokens or temperature are.
However, when we seek to go further in the use, it is necessary to understand these different concepts and this is what we will do now for the tokens.
Tokens are the LLM alphabet
Tokens are above all the way in which OpenAI and other LLM providers charge for their APIs, so in general everyone knows them.
What is less clear is understanding what a token corresponds to in relation to text and especially how many characters for a token.
You can think of tokens as pieces of words, where 1,000 tokens is about 750 words
OpenAI Pricing Page
A token would therefore be approximately 4 characters. However, this estimate is only valid for the English text.
In this example, the French text is split into 22% more tokens.


Moreover, even in the same language, the number of tokens is not linked to the number of characters.
In this example, the same number of characters produces 6% fewer tokens.

Tokens are a representation of the LLM alphabet. For example, LlaMa 3 has an “alphabet” of 128,000 tokens.
Each of these tokens is actually a number which corresponds to a series of letters.
We can also see these numbers in the Open AI online tokenizer tool:

The tokens are therefore comparable to Chinese ideograms where each ideogram corresponds to a concept.
For an LLM, each token also corresponds to an abstract internal concept having probabilistic relationships with other tokens just as the ideogram “dog” (狗) is often close to that for “bone” (骨).
The tokenizer to cut the text into tokens
A tokenizer is the algorithm that allows a text to be divided into a series of tokens.
Each LLM has its tokenizer, it is the latter which contains the correspondence table between the sequences of characters and the corresponding tokens.
The list of tokens is calculated in order to reduce as much as possible the number of tokens necessary to represent a text.
This list is constructed using character appearance statistics in different languages.
For example, OpenAI’s tokenizer is optimized to represent text in English and major European languages.
Plan the number of tokens to avoid unpleasant surprises
It is recommended to use the tokenizer of the LLM you wish to use in order to calculate the number of tokens in a text.
This makes it possible to evaluate the costs of a query precisely but also to avoid context window overflow errors when using an embedding model for example.
In Javascript and with Open AI, it is possible to use the @dqdb/tiktoken library:
import { encoding_for_model } from 'tiktoken'
// Choose the model, it can be 'gpt4' for example
const tokenEncoder = encoding_for_model('text-embedding-ada-002')
// Contains an array of Uint32 ([-0.102, 0.62, ..])
const tokens = tokenEncoder.encode(text)
// Number of tokens
console.log(tokens.length)
// Retrieve truncated text corresponding to 8096 tokens
const truncatedText = Buffer.from(
tokenEncoder.decode(tokens.slice(0, 8096))
).toString()
import { encoding_for_model } from 'tiktoken'
// Choose the model, it can be 'gpt4' for example
const tokenEncoder = encoding_for_model('text-embedding-ada-002')
// Contains an array of Uint32 ([-0.102, 0.62, ..])
const tokens = tokenEncoder.encode(text)
// Number of tokens
console.log(tokens.length)
// Retrieve truncated text corresponding to 8096 tokens
const truncatedText = Buffer.from(
tokenEncoder.decode(tokens.slice(0, 8096))
).toString()