
ChatGPT est très pratique pour obtenir rapidement des bouts de code ou des explications sur un sujet mais ça reste plus ou moins limité à une conversation.
Pour aller plus loin et interagir avec le monde réel, il faut utiliser des Agents LLM.
Dans cette série de deux articles, nous verrons comment créer un Agent LLM (en vérité 2 Agents) en utilisant Langchain et Node.js.
C’est quoi un Agent LLM
Le concept d’Agent est assez simple, c’est un pont entre la capacité de raisonnement d’un LLM et le monde réel.
On donne des possibilités d’interactions avec le monde réel via des actions comme faire une recherche sur Internet, exécuter une commande dans le terminal, lire/écrire du code, etc.
Dans le prompt, on va demander au LLM de résoudre une tâche en lui indiquant quelles sont les actions à sa disposition. Pour chacune de ces actions, il faudra être en mesure de parser la réponse du LLM et exécuter l’action correspondante.
Le résultat de chaque action devra être intégré dans le prompt pour que le LLM puisse poursuivre son raisonnement à chaque étape de la boucle d’exécution.
Donc si on résume, un Agent c’est:
- une tâche à résoudre
- une liste d’actions possibles
- un prompt dynamique
- une boucle d’exécution
Si vous souhaitez comprendre le fonctionnement d’un LLM, je vous recommande de regarder ces vidéos de ScienceEtonnante
Prompt de l’Agent LLM
Le prompt est la partie la plus importante de l’Agent. La qualité de votre prompt est déterminante pour la capacité de votre Agent à résoudre sa tâche
Un prompt comporte des parties fixes et des parties dynamiques qui varient au fur et à mesure des itérations nécessaire à la résolution de la tâche. On distingue 3 types de blocs:
- bloc d’instructions (fixe): on explique au LLM la tâche à résoudre et comment y parvenir
- bloc d’actions (fixe): liste des actions possibles
- bloc d’informations (dynamique): généralement le résultat des actions effectuées
Le but du LLM est de lire les instructions et les informations à sa disposition pour choisir la prochaine action à effectuer afin de résoudre la tâche.
Pour finir, le LLM doit être en mesure de d’indiquer que la tâche est résolue avec une autre action.
Par exemple, imaginons un agent très simple:
- la tâche est de récupérer 3 fruits dans un panier fictif
- notre Agent commencera avec un fruit
- une action matérialisée par le mot clé GetFruit(name) pour récupérer un fruit supplémentaire
- une action matérialisée par le mot clé Done() pour indiquer la fin de la tâche
Your task is to have 3 fruits in your basket.
You have the following fruits in your basket:
- banana
You can use the following actions:
- GetFruit(name): retrieve another fruit
- Done(): indicate that you finished your task En réponse à ce prompt, le LLM va renvoyer le mot clé GetFruit("cherry"). Nous allons donc mettre à jour le prompt afin d’itérer.
Your task is to have 3 fruits in your basket.
You have the following fruits in your basket:
- banana
- cherry
You can use the following actions:
- GetFruit(name): retrieve another fruit
- Done(): indicate that you finished your task Et nous continuerons nos itérations jusqu’à ce que le LLM considère la tâche comme terminée et renvoi le mot clé Done() dans sa réponse.
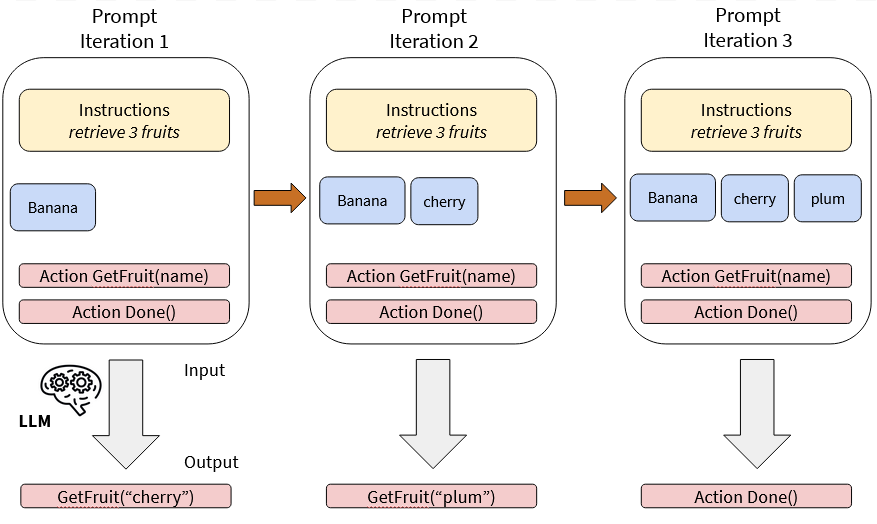
Schéma des itération successive du prompt envoyé au LLM
Pour en savoir plus sur les techniques d’optimisation des prompts 👉 https://gen-ai.fr/large-language-model/prompt-engineering-pour-un-agent-llm/
Boucle d’exécution de l’Agent LLM
Le cœur de l’Agent est sa boucle d’exécution qui va dans cet ordre:
- formater le prompt avec les informations dynamiques
- envoyer le prompt au LLM
- parser la réponse du LLM
- exécuter les actions choisies par le LLM
Le résultat de chaque action devra être stocké dans des variables afin de pouvoir l’intégrer dans la prochaine itération du prompt.
Exemple simplifié du code d’une boucle d’exécution d’un Agent:
function run () {
const promptTemplate = new PromptTemplate(`Your task is...`)
let done = false;
const fruits = ['banana'];
while (done === false) {
const prompt = await promptTemplate.format({ fruits });
const answer = await llm.call(prompt);
const actions = parseAnswer(answer);
for (const action of actions) {
if (action.name === 'GetFruit') {
fruits.push(action.parameters.fruit);
}
else if (action.name === 'Done') {
done = true;
}
}
}
}Toujours un peu flou pour vous? Ne vous en faites pas, un véritable exemple arrive dans la suite de l’article 😉
Notre tâche: debuguer du code Node.js
Pour cet exemple, nous allons choisir une tâche que nous faisons tous les jours: corriger un bug.
Résumons les étapes de correction d’un bug:
- lecture du message d’erreur
- lecture de la première fonction de la stacktrace
- lecture de toutes les fonctions utilisateur impliquées dans la calltrace (le bug peut venir de fonction qui ne sont pas présentes dans la stacktrace de l’erreur)
- compréhension du bug
- correction du bug
On remarque qu’il y a deux étapes dans la résolution d’un bug: une étape de recherche et une étape d’analyse.
Il serait possible de réaliser ces deux étapes dans le même Agent (et donc le même prompt) mais sa complexité augmenterait le risque d’hallucination, réduirait ses performances et bien sur cela le rend aussi plus difficile à maintenir.
En règle général, il est préférable de découper une tâche complexe en plusieurs sous-tâches et de créer un Agent par sous-tâche (de la même manière que nous pouvons découper un problème en plusieurs fonctions).
Premier Agent: lire le code des fonctions impliquées dans le bug
Pour la première sous-tâche, nous allons écrire un Agent capable de parcourir le code source de l’application pour récupérer le code des fonctions impliquées dans la callstack de notre erreur.
Exemple: Si l’erreur apparait dans la fonction createTask, alors il faut aussi lire les fonctions verifyTask, addTask, readTasksFromFile, generateId et writeTasksToFile qui sont réparties dans 3 fichiers.

Plutôt que de récupérer le fichier entier contenant les fonctions impliquées, nous allons récupérer uniquement le code de ces dernières. Cela nous permet d’économiser des caractères sur le prompt final. (limité à ~24000 pour GPT-4)
Nous appellerons ce premier Agent WalkCallStackAgent. Son entrée sera une stacktrace Javascript et sa sortie la liste des fonctions impliquées dans l’erreur.
WalkCallStackAgent – Prompt
La première partie de notre prompt est un bloc d’instructions (fixe) contenant la description de la tâche à réaliser avec la stacktrace correspondante.
Your goal is to retrieve every user function called from the first function referenced by this stacktrace:
{stacktrace}
For each user function, note the name of every function that is called and read the code of these functions.
Check the require statements in the user functions to know which files you need to read.
You can ask to read many function at once.Ensuite, la deuxième partie est un bloc d’informations (dynamique) contenant la liste des fonctions déjà lues. C’est ce bloc qui sera amené à évoluer à chaque itération de l’Agent.
You already have the code of the following user functions:
{userFunctions}Finalement, la dernière partie est un bloc d’actions (fixe). Les actions sont définies en utilisant une syntaxe XML simplifiée plus compréhensible que du JSON pour un LLM car plus proche du langage naturel.
Decide if you need to read the code of more user function or if you are done because you have the code of all the user function.
You can use the following actions:
<Action name="READ_FUNCTION">
<Parameter name="filepath">
// path to the file containing the function
</Parameter>
<Parameter name="functionName">
// name of the function
</Parameter>
</Action>
<Action name="DONE"></Action>
Answer only with your next actions. WalkCallStackAgent – Code
Il est temps d’ouvrir un IDE pour coder concrètement notre agent. Nous allons encapsuler toute la logique nécessaire dans une classe:
- template de prompt
- boucle d’exécution
- appel au LLM GPT-4 d’OpenAI
- parsing des actions dans la réponse du LLM
- action de lecture du code d’une fonction
On commence par l’initialisation de notre classe avec notre prompt et l’instance du LLM utilisé (ici GPT-4)
import { OpenAI } from "langchain/llms/openai";
import { PromptTemplate } from "langchain/prompts";
export class WalkCallStackAgent {
// Initialize OpenAI GPT-4 model
private llm = new OpenAI({
modelName: "gpt-4",
temperature: 0.0,
maxTokens: -1,
});
// Our prompt with declaration of templated variables
private promptTemplate = new PromptTemplate({
template: `Your goal is [...]`,
inputVariables: ["stacktrace", "userFunctions"],
});
// The stacktrace we want to analyze
private stacktrace: string;
// The list of functions we already read
public userFunctions: string[] = [];
constructor({ stacktrace }: { stacktrace: string }) {
this.stacktrace = stacktrace;
}
async run() {
}
private async executeAction(action: string, parameters: any) {
}
log(text: string) {
console.log(`WalkCallStackAgent: ${text}`);
}
}Nous avons la base de notre agent, à présent ajoutons la méthode run qui contient la boucle d’exécution.
La méthode executeAction sera détaillée après et le code de extractActions ne présente que peu d’intêret, il parse simplement la réponse XML du LLM et le code a été généré ChatGPT.
On va également ajouter un mécanisme pour sauvegarder nos prompts et les réponses du LLM afin de les lire plus tard pour debuguer au besoin.
async run() {
let i = 0;
let done = false;
this.log("start retrieving user functions");
while (!done) {
this.log(`${this.userFunctions.length} user functions found`);
// We format the prompt by providing the template variables
const prompt = await this.promptTemplate.format({
stacktrace: this.stacktrace,
userFunctions: this.userFunctions.join("\n"),
});
// Call to the LLM with our prompt
const answer = await this.llm.call(prompt);
writeFileSync(`./prompt-${i++}.txt`, prompt + "\n----\n" + answer);
// Parse the LLM answer to extract next actions
const actions = extractActions(answer);
for (const { action, parameters } of actions) {
// executeAction will return true if we should stop the loop
done = await this.executeAction(action, parameters);
}
}
}Voyons maintenant le code de la méthode executeAction. Ici aussi je ne m’attarderais pas sur le code utiliser pour lire le code de getFunctionCodeWithRequire car je l’ai aussi fait générer par ChatGPT.
private async executeAction(action: string, parameters: any) {
switch (action) {
case "READ_FUNCTION":
this.log(
`Read code of function "${parameters.functionName}" in file "${parameters.filepath}"`
);
// Read the code of a function in a file and add the require statements
const functionCode = getFunctionCodeWithRequire(
parameters.filepath,
parameters.functionName
);
this.userFunctions.push(functionCode);
return false;
case "DONE":
this.log(`finished`);
return true;
default:
throw new Error(`Unknown action: ${action}`);
}
}La fonction getFunctionCodeWithRequire va lire le code d’une fonction dans un fichier en parcourant l’AST ainsi que les appels à require pour que le LLM puisse comprendre dans quels fichiers aller lire les fonctions suivantes (aussi généré par ChatGPT).
Le résultat de cette fonction contient le chemin et le nom de la fonction ainsi que le code dans ce format:
filepath: /home/aschen/bug-agent/example/app.js
functionName: createTask
```ts
const database = require('/home/aschen/bug-agent/example/database.js');
const { verifyTask } = require('/home/aschen/bug-agent/example/verify.js');
function createTask (req, res) {
const newTask = req.body;
verifyTask(newTask);
const savedTask = database.addTask(newTask);
res.status(201).send(`Task ${savedTask.metadata.id} saved successfully`);
}
```WalkCallStackAgent – Execution
En reprenant notre exemple de callstack énoncé plus haut, la résolution de la tâche par l’Agent se fera en 4 tours de boucle:
- Tour 0: le prompt ne contient que la stacktrace, le LLM va donc demander à lire la dernière fonction appelée (
createTask) - Tour 1: le prompt contient le code de la fonction
createTask, le LLM demande à lireaddTasketverifyTask - Tour 2: le prompt contient le code de nos 3 fonctions précédentes, le LLM demande lire les 3 dernières fonctions appelées dans
addTask - Tour 3: le prompt contient le code de nos 6 fonctions, le LLM ne voit plus d’autres fonctions à lire alors il indique que sa tâche est terminée
$ bun run run.ts
WalkCallStackAgent: start retrieving user functions
WalkCallStackAgent: 0 user functions found
WalkCallStackAgent: Read code of function "createTask" in file "example/app.js"
WalkCallStackAgent: 1 user functions found
WalkCallStackAgent: Read code of function "addTask" in file "./example/database"
WalkCallStackAgent: Read code of function "verifyTask" in file "./example/verify"
WalkCallStackAgent: 3 user functions found
WalkCallStackAgent: Read code of function "readTasksFromFile" in file "./example/database"
WalkCallStackAgent: Read code of function "generateId" in file "./example/database"
WalkCallStackAgent: Read code of function "writeTasksToFile" in file "./example/database"
WalkCallStackAgent: 6 user functions found
WalkCallStackAgent: finishedConclusion
Dans cette première partie, nous avons vu le principe de fonctionnement d’un Agent LLM avec l’utilisation d’un prompt dynamique pour représenter le progrès dans l’aboutissement d’une tâche.
L’Agent développé ici est assez simpliste mais néanmoins capable d’un raisonnement avancé pour repérer les appels à des fonctions utilisateur uniquement (il ne demande pas à lire le code de writeFileSync par exemple) et comprendre quand s’arrêter car il a tout lu.
Dans le prochain article, nous verrons comment enchainer plusieurs Agents pour résoudre notre tâche de debug d’erreur Node.js.
Pour finir, le code de cet article est disponible sur Github: https://github.com/Aschen/llm-experiments/tree/master/article-agent-llm
Voir la partie 2 👉 https://gen-ai.fr/large-language-model/creer-un-agent-llm-en-node-js-partie-2/


